一�����、PyTorch 檢查模型梯度是否可導
當我們構(gòu)建復雜網(wǎng)絡模型或在模型中加入復雜操作時�,可能會需要驗證該模型或操作是否可導,即模型是否能夠優(yōu)化�,在PyTorch框架下,我們可以使用torch.autograd.gradcheck函數(shù)來實現(xiàn)這一功能�。
首先看一下官方文檔中關(guān)于該函數(shù)的介紹:
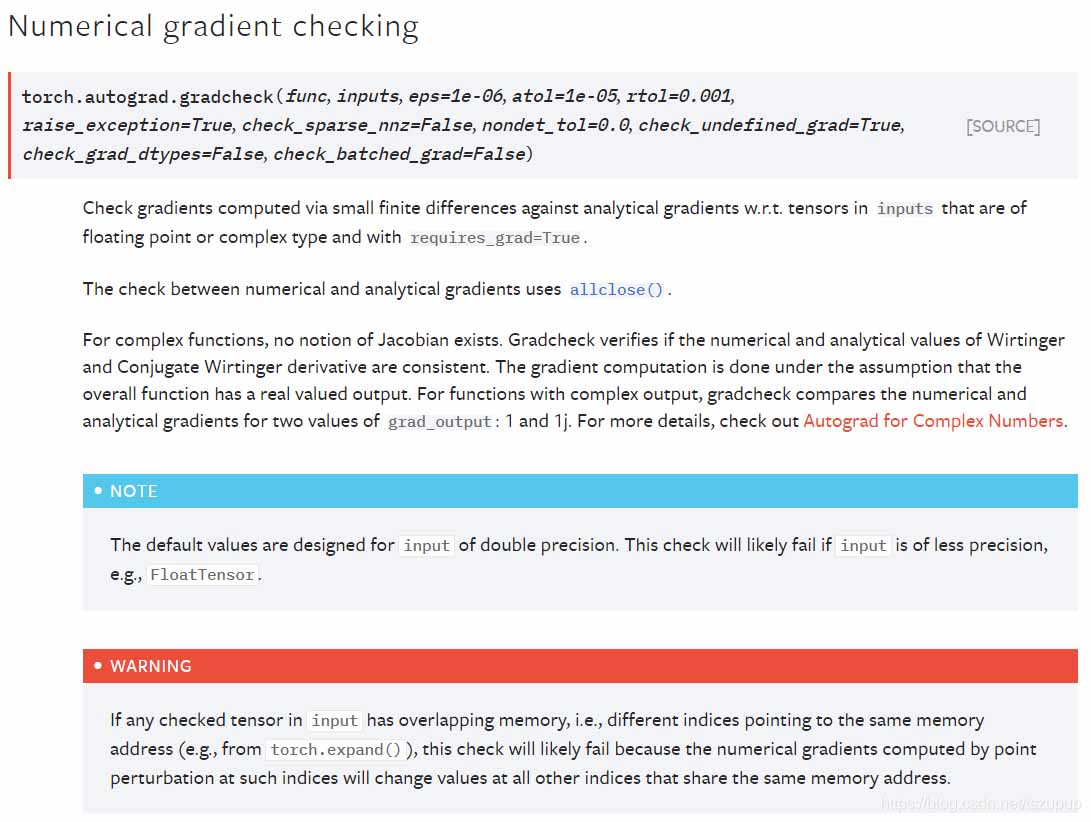
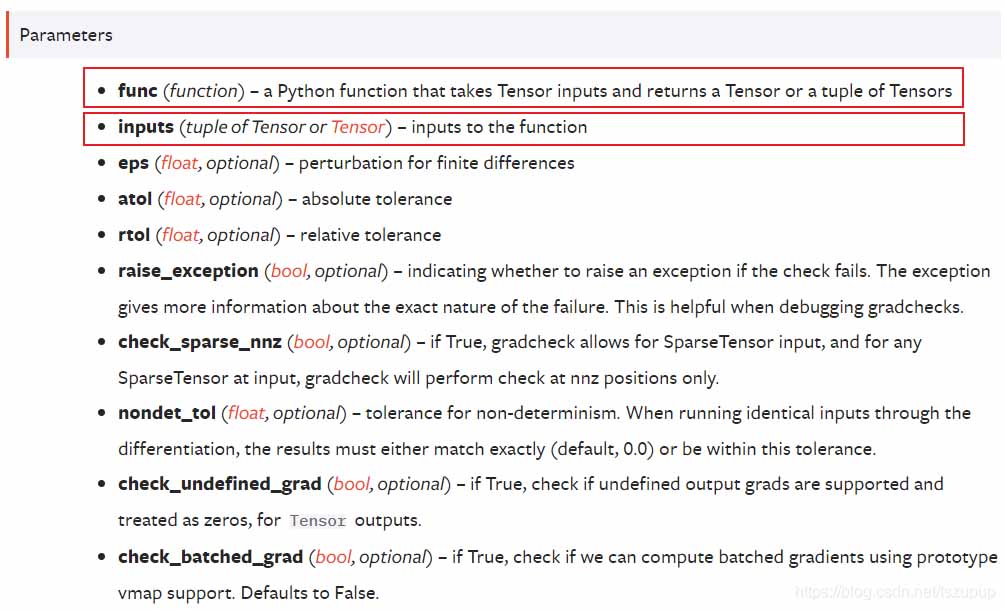
可以看到官方文檔中介紹了該函數(shù)基于何種方法���,以及其參數(shù)列表,下面給出幾個例子介紹其使用方法���,注意:
Tensor需要是雙精度浮點型且設置requires_grad = True
第一個例子:檢查某一操作是否可導
from torch.autograd import gradcheck
import torch
import torch.nn as nn
inputs = torch.randn((10, 5), requires_grad=True, dtype=torch.double)
linear = nn.Linear(5, 3)
linear = linear.double()
test = gradcheck(lambda x: linear(x), inputs)
print("Are the gradients correct: ", test)
輸出為:
Are the gradients correct: True
第二個例子:檢查某一網(wǎng)絡模型是否可導
from torch.autograd import gradcheck
import torch
import torch.nn as nn
# 定義神經(jīng)網(wǎng)絡模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.net = nn.Sequential(
nn.Linear(15, 30),
nn.ReLU(),
nn.Linear(30, 15),
nn.ReLU(),
nn.Linear(15, 1),
nn.Sigmoid()
)
def forward(self, x):
y = self.net(x)
return y
net = Net()
net = net.double()
inputs = torch.randn((10, 15), requires_grad=True, dtype=torch.double)
test = gradcheck(net, inputs)
print("Are the gradients correct: ", test)
輸出為:
Are the gradients correct: True
二�、Pytorch求導
1.標量對矩陣求導

驗證:
>>>import torch
>>>a = torch.tensor([[1],[2],[3.],[4]]) # 4*1列向量
>>>X = torch.tensor([[1,2,3],[5,6,7],[8,9,10],[5,4,3.]],requires_grad=True) #4*3矩陣�,注意,值必須要是float類型
>>>b = torch.tensor([[2],[3],[4.]]) #3*1列向量
>>>f = a.view(1,-1).mm(X).mm(b) # f = a^T.dot(X).dot(b)
>>>f.backward()
>>>X.grad #df/dX = a.dot(b^T)
tensor([[ 2., 3., 4.],
[ 4., 6., 8.],
[ 6., 9., 12.],
[ 8., 12., 16.]])
>>>a.grad b.grad # a和b的requires_grad都為默認(默認為False)��,所以求導時�,沒有梯度
(None, None)
>>>a.mm(b.view(1,-1)) # a.dot(b^T)
tensor([[ 2., 3., 4.],
[ 4., 6., 8.],
[ 6., 9., 12.],
[ 8., 12., 16.]])
2.矩陣對矩陣求導
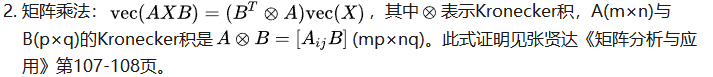

驗證:
>>>A = torch.tensor([[1,2],[3,4.]]) #2*2矩陣
>>>X = torch.tensor([[1,2,3],[4,5.,6]],requires_grad=True) # 2*3矩陣
>>>F = A.mm(X)
>>>F
tensor([[ 9., 12., 15.],
[19., 26., 33.]], grad_fn=MmBackward>)
>>>F.backgrad(torch.ones_like(F)) # 注意括號里要加上這句
>>>X.grad
tensor([[4., 4., 4.],
[6., 6., 6.]])
注意:
requires_grad為True的數(shù)組必須是float類型
進行backgrad的必須是標量,如果是向量����,必須在后面括號里加上torch.ones_like(X)
以上為個人經(jīng)驗����,希望能給大家一個參考,也希望大家多多支持腳本之家��。
您可能感興趣的文章:- Pytorch通過保存為ONNX模型轉(zhuǎn)TensorRT5的實現(xiàn)
- pytorch_pretrained_bert如何將tensorflow模型轉(zhuǎn)化為pytorch模型
- pytorch模型的保存和加載����、checkpoint操作
- 解決Pytorch修改預訓練模型時遇到key不匹配的情況
- pytorch 預訓練模型讀取修改相關(guān)參數(shù)的填坑問題
- PyTorch模型轉(zhuǎn)TensorRT是怎么實現(xiàn)的?
