前言
隨著大數(shù)據(jù)時代的到來,機器學(xué)習(xí)成為解決問題的一種重要且關(guān)鍵的工具。不管是工業(yè)界還是學(xué)術(shù)界���,機器學(xué)習(xí)都是一個炙手可熱的方向�,但是學(xué)術(shù)界和工業(yè)界對機器學(xué)習(xí)的研究各有側(cè)重�,學(xué)術(shù)界側(cè)重于對機器學(xué)習(xí)理論的研究,工業(yè)界側(cè)重于如何用機器學(xué)習(xí)來解決實際問題���。我們結(jié)合美團在機器學(xué)習(xí)上的實踐��,進行一個實戰(zhàn)(InAction)系列的介紹(帶“機器學(xué)習(xí)InAction系列”標簽的文章)�,介紹機器學(xué)習(xí)在解決工業(yè)界問題的實戰(zhàn)中所需的基本技術(shù)���、經(jīng)驗和技巧����。本文主要結(jié)合實際問題�����,概要地介紹機器學(xué)習(xí)解決實際問題的整個流程�����,包括對問題建模、準備訓(xùn)練數(shù)據(jù)�����、抽取特征����、訓(xùn)練模型和優(yōu)化模型等關(guān)鍵環(huán)節(jié)�;另外幾篇則會對這些關(guān)鍵環(huán)節(jié)進行更深入地介紹。
下文分為1)機器學(xué)習(xí)的概述���,2)對問題建模�����,3)準備訓(xùn)練數(shù)據(jù)�,4)抽取特征�����,5)訓(xùn)練模型���,6)優(yōu)化模型����,7)總結(jié) 共7個章節(jié)進行介紹。
機器學(xué)習(xí)的概述:
###什么是機器學(xué)習(xí)�����?
隨著機器學(xué)習(xí)在實際工業(yè)領(lǐng)域中不斷獲得應(yīng)用��,這個詞已經(jīng)被賦予了各種不同含義���。在本文中的“機器學(xué)習(xí)”含義與wikipedia上的解釋比較契合��,如下:
Machine learning is a scientific discipline that deals with the construction and study of algorithms that can learn from data.
機器學(xué)習(xí)可以分為無監(jiān)督學(xué)習(xí)(unsupervised learning)和有監(jiān)督學(xué)習(xí)(supervised learning)����,在工業(yè)界中���,有監(jiān)督學(xué)習(xí)是更常見和更有價值的方式�����,下文中主要以這種方式展開介紹���。如下圖中所示���,有監(jiān)督的機器學(xué)習(xí)在解決實際問題時,有兩個流程���,一個是離線訓(xùn)練流程(藍色箭頭)���,包含數(shù)據(jù)篩選和清洗�、特征抽取、模型訓(xùn)練和優(yōu)化模型等環(huán)節(jié)�����;另一個流程則是應(yīng)用流程(綠色箭頭)���,對需要預(yù)估的數(shù)據(jù)�,抽取特征����,應(yīng)用離線訓(xùn)練得到的模型進行預(yù)估,獲得預(yù)估值作用在實際產(chǎn)品中����。在這兩個流程中����,離線訓(xùn)練是最有技術(shù)挑戰(zhàn)的工作(在線預(yù)估流程很多工作可以復(fù)用離線訓(xùn)練流程的工作)�,所以下文主要介紹離線訓(xùn)練流程。
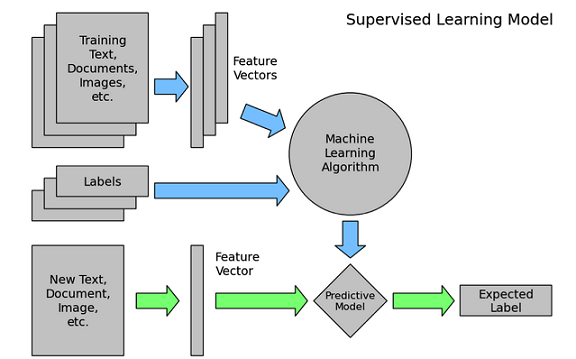
###什么是模型(model)�����?
模型�,是機器學(xué)習(xí)中的一個重要概念,簡單的講���,指特征空間到輸出空間的映射���;一般由模型的假設(shè)函數(shù)和參數(shù)w組成(下面公式就是Logistic Regression模型的一種表達,在訓(xùn)練模型的章節(jié)做稍詳細的解釋)��;一個模型的假設(shè)空間(hypothesis space)���,指給定模型所有可能w對應(yīng)的輸出空間組成的集合����。工業(yè)界常用的模型有Logistic Regression(簡稱LR)����、Gradient Boosting Decision Tree(簡稱GBDT)�����、Support Vector Machine(簡稱SVM)����、Deep Neural Network(簡稱DNN)等����。
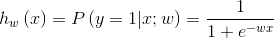
模型訓(xùn)練就是基于訓(xùn)練數(shù)據(jù)��,獲得一組參數(shù)w��,使得特定目標最優(yōu)����,即獲得了特征空間到輸出空間的最優(yōu)映射,具體怎么實現(xiàn)��,見訓(xùn)練模型章節(jié)��。
###為什么要用機器學(xué)習(xí)解決問題�?
目前處于大數(shù)據(jù)時代����,到處都有成T成P的數(shù)據(jù)����,簡單規(guī)則處理難以發(fā)揮這些數(shù)據(jù)的價值;
廉價的高性能計算��,使得基于大規(guī)模數(shù)據(jù)的學(xué)習(xí)時間和代價降低����;
廉價的大規(guī)模存儲,使得能夠更快地和代價更小地處理大規(guī)模數(shù)據(jù)�����;
存在大量高價值的問題����,使得花大量精力用機器學(xué)習(xí)解決問題后,能獲得豐厚收益���。
###機器學(xué)習(xí)應(yīng)該用于解決什么問題����?
目標問題需要價值巨大,因為機器學(xué)習(xí)解決問題有一定的代價�����;
目標問題有大量數(shù)據(jù)可用���,有大量數(shù)據(jù)才能使機器學(xué)習(xí)比較好地解決問題(相對于簡單規(guī)則或人工)�����;
目標問題由多種因素(特征)決定����,機器學(xué)習(xí)解決問題的優(yōu)勢才能體現(xiàn)(相對于簡單規(guī)則或人工)��;
目標問題需要持續(xù)優(yōu)化��,因為機器學(xué)習(xí)可以基于數(shù)據(jù)自我學(xué)習(xí)和迭代�����,持續(xù)地發(fā)揮價值���。
對問題建模
本文以DEAL(團購單)交易額預(yù)估問題為例(就是預(yù)估一個給定DEAL一段時間內(nèi)賣了多少錢)��,介紹使用機器學(xué)習(xí)如何解決問題��。首先需要:
收集問題的資料���,理解問題,成為這個問題的專家��;
拆解問題���,簡化問題����,將問題轉(zhuǎn)化機器可預(yù)估的問題����。
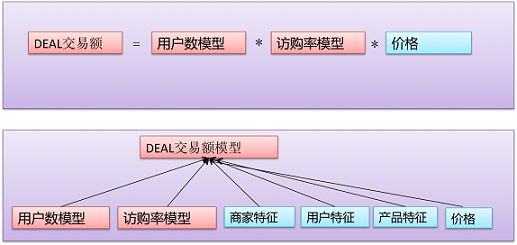
深入理解和分析DEAL交易額后,可以將它分解為如下圖的幾個問題:
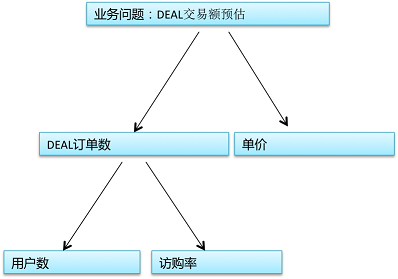
###單個模型���?多個模型��?如何來選擇��?
按照上圖進行拆解后�,預(yù)估DEAL交易額就有2種可能模式,一種是直接預(yù)估交易額����;另一種是預(yù)估各子問題,如建立一個用戶數(shù)模型和建立一個訪購率模型(訪問這個DEAL的用戶會購買的單子數(shù))�,再基于這些子問題的預(yù)估值計算交易額。
不同方式有不同優(yōu)缺點�,具體如下:
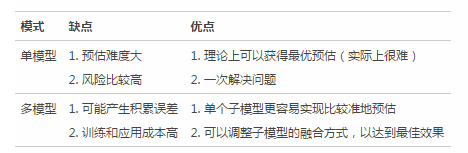
選擇哪種模式?
1)問題可預(yù)估的難度�����,難度大����,則考慮用多模型;
2)問題本身的重要性�����,問題很重要���,則考慮用多模型;
3)多個模型的關(guān)系是否明確,關(guān)系明確����,則可以用多模型。
如果采用多模型�����,如何融合��?
可以根據(jù)問題的特點和要求進行線性融合�,或進行復(fù)雜的融合。以本文問題為例����,至少可以有如下兩種:
###模型選擇
對于DEAL交易額這個問題,我們認為直接預(yù)估難度很大��,希望拆成子問題進行預(yù)估�����,即多模型模式��。那樣就需要建立用戶數(shù)模型和訪購率模型����,因為機器學(xué)習(xí)解決問題的方式類似�����,下文只以訪購率模型為例���。要解決訪購率問題,首先要選擇模型�,我們有如下的一些考慮:
主要考慮
1)選擇與業(yè)務(wù)目標一致的模型;
2)選擇與訓(xùn)練數(shù)據(jù)和特征相符的模型�����。
訓(xùn)練數(shù)據(jù)少��,High Level特征多�,則使用“復(fù)雜”的非線性模型(流行的GBDT、Random Forest等)����;
訓(xùn)練數(shù)據(jù)很大量,Low Level特征多�,則使用“簡單”的線性模型(流行的LR、Linear-SVM等)����。
補充考慮
1)當前模型是否被工業(yè)界廣泛使用;
2)當前模型是否有比較成熟的開源工具包(公司內(nèi)或公司外)�����;
3)當前工具包能夠的處理數(shù)據(jù)量能否滿足要求����;
4)自己對當前模型理論是否了解,是否之前用過該模型解決問題�。
為實際問題選擇模型,需要轉(zhuǎn)化問題的業(yè)務(wù)目標為模型評價目標�����,轉(zhuǎn)化模型評價目標為模型優(yōu)化目標���;根據(jù)業(yè)務(wù)的不同目標���,選擇合適的模型,具體關(guān)系如下:
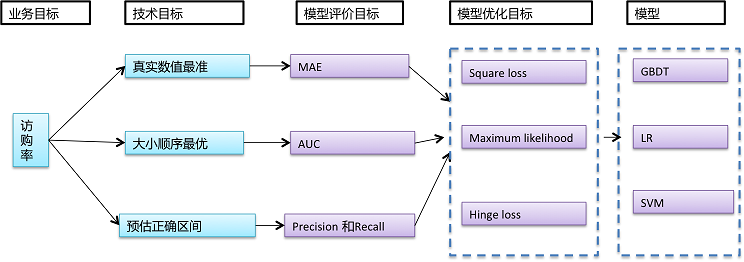
通常來講�,預(yù)估真實數(shù)值(回歸)、大小順序(排序)�����、目標所在的正確區(qū)間(分類)的難度從大到小,根據(jù)應(yīng)用所需��,盡可能選擇難度小的目標進行���。對于訪購率預(yù)估的應(yīng)用目標來說����,我們至少需要知道大小順序或真實數(shù)值��,所以我們可以選擇Area Under Curve(AUC)或Mean Absolute Error(MAE)作為評估目標�����,以Maximum likelihood為模型損失函數(shù)(即優(yōu)化目標)����。綜上所述,我們選擇spark版本 GBDT或LR�,主要基于如下考慮:
1)可以解決排序或回歸問題;
2)我們自己實現(xiàn)了算法���,經(jīng)常使用��,效果很好����;
3)支持海量數(shù)據(jù)����;
4)工業(yè)界廣泛使用。
準備訓(xùn)練數(shù)據(jù)
深入理解問題�,針對問題選擇了相應(yīng)的模型后,接下來則需要準備數(shù)據(jù)�;數(shù)據(jù)是機器學(xué)習(xí)解決問題的根本,數(shù)據(jù)選擇不對�,則問題不可能被解決,所以準備訓(xùn)練數(shù)據(jù)需要格外的小心和注意:
###注意點:
待解決問題的數(shù)據(jù)本身的分布盡量一致�����;
訓(xùn)練集/測試集分布與線上預(yù)測環(huán)境的數(shù)據(jù)分布盡可能一致�,這里的分布是指(x,y)的分布,不僅僅是y的分布�����;
y數(shù)據(jù)噪音盡可能小����,盡量剔除y有噪音的數(shù)據(jù)��;
非必要不做采樣�����,采樣常?����?赡苁箤嶋H數(shù)據(jù)分布發(fā)生變化��,但是如果數(shù)據(jù)太大無法訓(xùn)練或者正負比例嚴重失調(diào)(如超過100:1),則需要采樣解決���。
###常見問題及解決辦法
待解決問題的數(shù)據(jù)分布不一致:
1)訪購率問題中DEAL數(shù)據(jù)可能差異很大,如美食DEAL和酒店DEAL的影響因素或表現(xiàn)很不一致�,需要做特別處理;要么對數(shù)據(jù)提前歸一化�����,要么將分布不一致因素作為特征�����,要么對各類別DEAL單獨訓(xùn)練模型。
數(shù)據(jù)分布變化了:
1)用半年前的數(shù)據(jù)訓(xùn)練模型��,用來預(yù)測當前數(shù)據(jù)���,因為數(shù)據(jù)分布隨著時間可能變化了��,效果可能很差�����。盡量用近期的數(shù)據(jù)訓(xùn)練,來預(yù)測當前數(shù)據(jù)�����,歷史的數(shù)據(jù)可以做降權(quán)用到模型��,或做transfer learning���。
y數(shù)據(jù)有噪音:
1)在建立CTR模型時�,將用戶沒有看到的Item作為負例���,這些Item是因為用戶沒有看到才沒有被點擊����,不一定是用戶不喜歡而沒有被點擊,所以這些Item是有噪音的����。可以采用一些簡單規(guī)則��,剔除這些噪音負例�,如采用skip-above思想,即用戶點過的Item之上��,沒有點過的Item作為負例(假設(shè)用戶是從上往下瀏覽Item)����。
采樣方法有偏,沒有覆蓋整個集合:
1)訪購率問題中���,如果只取只有一個門店的DEAL進行預(yù)估����,則對于多門店的DEAL無法很好預(yù)估����。應(yīng)該保證一個門店的和多個門店的DEAL數(shù)據(jù)都有�;
2)無客觀數(shù)據(jù)的二分類問題��,用規(guī)則來獲得正/負例��,規(guī)則對正/負例的覆蓋不全面����。應(yīng)該隨機抽樣數(shù)據(jù),進行人工標注����,以確保抽樣數(shù)據(jù)和實際數(shù)據(jù)分布一致���。
###訪購率問題的訓(xùn)練數(shù)據(jù)
收集N個月的DEAL數(shù)據(jù)(x)及相應(yīng)訪購率(y)���;
收集最近N個月,剔除節(jié)假日等非常規(guī)時間 (保持分布一致)����;
只收集在線時長>T 且 訪問用戶數(shù) > U的DEAL (減少y的噪音);
考慮DEAL銷量生命周期 (保持分布一致)��;
考慮不同城市、不同商圈��、不同品類的差別 (保持分布一致)��。
抽取特征
完成數(shù)據(jù)篩選和清洗后�����,就需要對數(shù)據(jù)抽取特征����,就是完成輸入空間到特征空間的轉(zhuǎn)換(見下圖)。針對線性模型或非線性模型需要進行不同特征抽取�����,線性模型需要更多特征抽取工作和技巧����,而非線性模型對特征抽取要求相對較低。
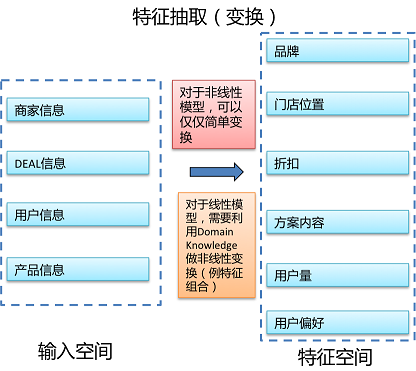
通常���,特征可以分為High Level與Low Level�,High Level指含義比較泛的特征����,Low Level指含義比較特定的特征����,舉例來說:
DEAL A1屬于POIA��,人均50以下���,訪購率高�;
DEAL A2屬于POIA����,人均50以上,訪購率高����;
DEAL B1屬于POIB�����,人均50以下�����,訪購率高;
DEAL B2屬于POIB�,人均50以上,訪購率底��;
基于上面的數(shù)據(jù)�,可以抽到兩種特征,POI(門店)或人均消費��;POI特征則是Low Level特征��,人均消費則是High Level特征���;假設(shè)模型通過學(xué)習(xí)���,獲得如下預(yù)估:
如果DEALx 屬于POIA(Low Level feature),訪購率高�;
如果DEALx 人均50以下(High Level feature),訪購率高����。
所以,總體上����,Low Level 比較有針對性���,單個特征覆蓋面小(含有這個特征的數(shù)據(jù)不多)�,特征數(shù)量(維度)很大。High Level比較泛化�,單個特征覆蓋面大(含有這個特征的數(shù)據(jù)很多),特征數(shù)量(維度)不大�。長尾樣本的預(yù)測值主要受High Level特征影響。高頻樣本的預(yù)測值主要受Low Level特征影響�。
對于訪購率問題,有大量的High Level或Low Level的特征��,其中一些展示在下圖:

非線性模型的特征
1)可以主要使用High Level特征���,因為計算復(fù)雜度大����,所以特征維度不宜太高����;
2)通過High Level非線性映射可以比較好地擬合目標。
線性模型的特征
1)特征體系要盡可能全面����,High Level和Low Level都要有;
2)可以將High Level轉(zhuǎn)換Low Level�,以提升模型的擬合能力。
###特征歸一化
特征抽取后���,如果不同特征的取值范圍相差很大�����,最好對特征進行歸一化���,以取得更好的效果,常見的歸一化方式如下:
Rescaling:
歸一化到[0,1] 或 [-1���,1]�����,用類似方式:
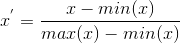
Standardization:
設(shè)為x分布的均值�,為x分布的標準差���;
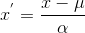
Scaling to unit length:
歸一化到單位長度向量
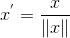
###特征選擇
特征抽取和歸一化之后��,如果發(fā)現(xiàn)特征太多�����,導(dǎo)致模型無法訓(xùn)練����,或很容易導(dǎo)致模型過擬合,則需要對特征進行選擇�����,挑選有價值的特征���。
Filter:
假設(shè)特征子集對模型預(yù)估的影響互相獨立��,選擇一個特征子集�����,分析該子集和數(shù)據(jù)Label的關(guān)系����,如果存在某種正相關(guān)���,則認為該特征子集有效�����。衡量特征子集和數(shù)據(jù)Label關(guān)系的算法有很多�����,如Chi-square�,Information Gain���。
Wrapper:
選擇一個特征子集加入原有特征集合��,用模型進行訓(xùn)練��,比較子集加入前后的效果��,如果效果變好��,則認為該特征子集有效�,否則認為無效����。
Embedded:
將特征選擇和模型訓(xùn)練結(jié)合起來,如在損失函數(shù)中加入L1 Norm ,L2 Norm���。
訓(xùn)練模型
完成特征抽取和處理后���,就可以開始模型訓(xùn)練了,下文以簡單且常用的Logistic Regression模型(下稱LR模型)為例�,進行簡單介紹。
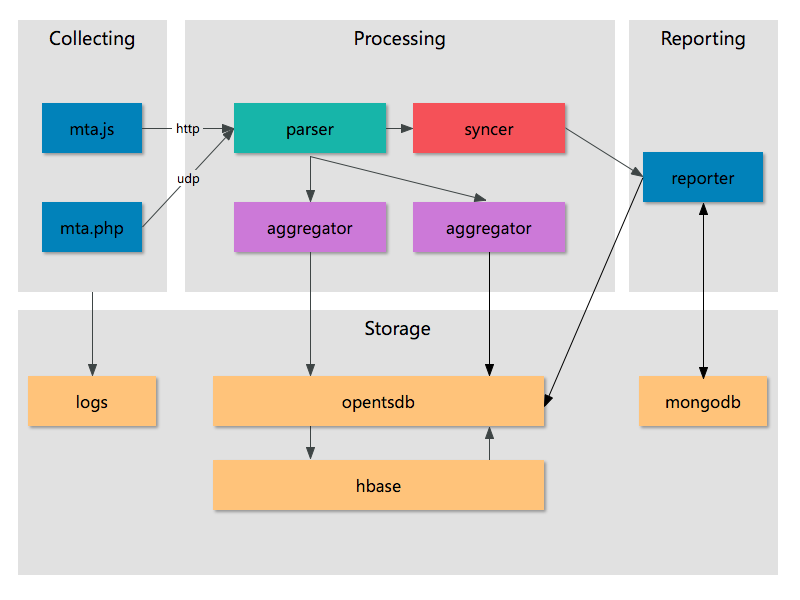
設(shè)有m個(x,y)訓(xùn)練數(shù)據(jù)�,其中x為特征向量,y為label����,
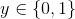
;w為模型中參數(shù)向量���,即模型訓(xùn)練中需要學(xué)習(xí)的對象���。
所謂訓(xùn)練模型,就是選定假說函數(shù)和損失函數(shù)�,基于已有訓(xùn)練數(shù)據(jù)(x,y),不斷調(diào)整w�,使得損失函數(shù)最優(yōu),相應(yīng)的w就是最終學(xué)習(xí)結(jié)果�����,也就得到相應(yīng)的模型。
###模型函數(shù)
1)假說函數(shù)��,即假設(shè)x和y存在一種函數(shù)關(guān)系:
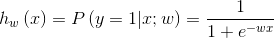
2)損失函數(shù)��,基于上述假設(shè)函數(shù)����,構(gòu)建模型損失函數(shù)(優(yōu)化目標)�����,在LR中通常以(x,y)的最大似然估計為目標:
###優(yōu)化算法
梯度下降(Gradient Descent)
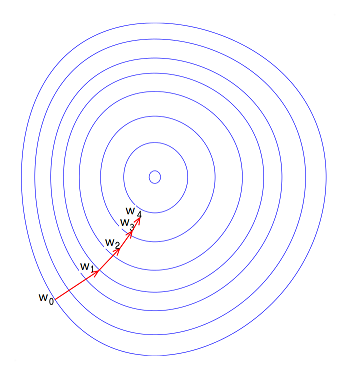
即w沿著損失函數(shù)的負梯度方向進行調(diào)整���,示意圖見下圖��,的梯度即一階導(dǎo)數(shù)(見下式)��,梯度下降有多種類型����,如隨機梯度下降或批量梯度下降����。

隨機梯度下降(Stochastic Gradient Descent)��,每一步隨機選擇一個樣本�,計算相應(yīng)的梯度���,并完成w的更新�����,如下式�����,
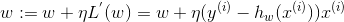
批量梯度下降(Batch Gradient Descent),每一步都計算訓(xùn)練數(shù)據(jù)中的所有樣本對應(yīng)的梯度�����,w沿著這個梯度方向迭代���,即
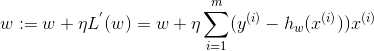
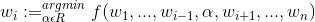
牛頓法(Newton’s Method)
牛頓法的基本思想是在極小點附近通過對目標函數(shù)做二階Taylor展開,進而找到L(w)的極小點的估計值���。形象地講���,在wk處做切線����,該切線與L(w)=0的交點即為下一個迭代點wk+1(示意圖如下)�。w的更新公式如下,其中目標函數(shù)的二階偏導(dǎo)數(shù)����,即為大名鼎鼎的Hessian矩陣。
擬牛頓法(Quasi-Newton Methods):計算目標函數(shù)的二階偏導(dǎo)數(shù)��,難度較大�,更為復(fù)雜的是目標函數(shù)的Hessian矩陣無法保持正定�����;不用二階偏導(dǎo)數(shù)而構(gòu)造出可以近似Hessian矩陣的逆的正定對稱陣����,從而在"擬牛頓"的條件下優(yōu)化目標函數(shù)。
BFGS: 使用BFGS公式對H(w)進行近似����,內(nèi)存中需要放H(w),內(nèi)存需要O(m2)級別�;
L-BFGS:存儲有限次數(shù)(如k次)的更新矩陣
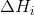
���,用這些更新矩陣生成新的H(w),內(nèi)存降至O(m)級別���;
OWLQN: 如果在目標函數(shù)中引入L1正則化,需要引入虛梯度來解決目標函數(shù)不可導(dǎo)問題��,OWLQN就是用來解決這個問題����。
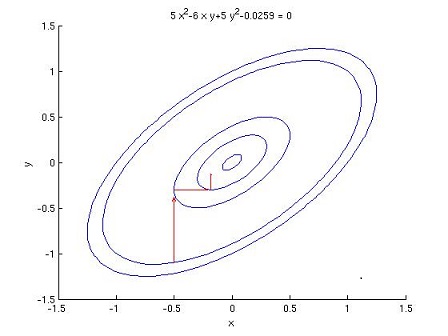
Coordinate Descent
對于w,每次迭代��,固定其他維度不變�,只對其一個維度進行搜索,確定最優(yōu)下降方向(示意圖如下)���,公式表達如下:
優(yōu)化模型
經(jīng)過上文提到的數(shù)據(jù)篩選和清洗�����、特征設(shè)計和選擇�����、模型訓(xùn)練�����,就得到了一個模型�����,但是如果發(fā)現(xiàn)效果不好�����?怎么辦���?
【首先】
反思目標是否可預(yù)估,數(shù)據(jù)和特征是否存在bug�����。
【然后】
分析一下模型是Overfitting還是Underfitting�����,從數(shù)據(jù)���、特征和模型等環(huán)節(jié)做針對性優(yōu)化�。
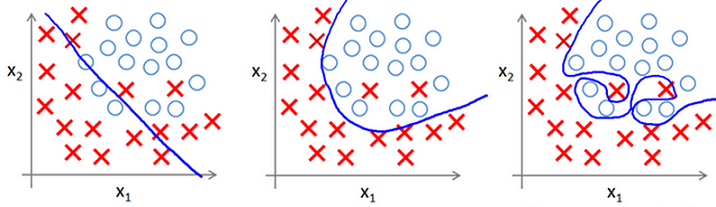
###Underfitting Overfitting
所謂Underfitting,即模型沒有學(xué)到數(shù)據(jù)內(nèi)在關(guān)系����,如下圖左一所示,產(chǎn)生分類面不能很好的區(qū)分X和O兩類數(shù)據(jù)����;產(chǎn)生的深層原因,就是模型假設(shè)空間太小或者模型假設(shè)空間偏離��。
所謂Overfitting�,即模型過渡擬合了訓(xùn)練數(shù)據(jù)的內(nèi)在關(guān)系,如下圖右一所示����,產(chǎn)生分類面過好地區(qū)分X和O兩類數(shù)據(jù),而真實分類面可能并不是這樣�,以至于在非訓(xùn)練數(shù)據(jù)上表現(xiàn)不好;產(chǎn)生的深層原因�,是巨大的模型假設(shè)空間與稀疏的數(shù)據(jù)之間的矛盾。
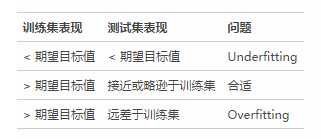
在實戰(zhàn)中����,可以基于模型在訓(xùn)練集和測試集上的表現(xiàn)來確定當前模型到底是Underfitting還是Overfitting����,判斷方式如下表:
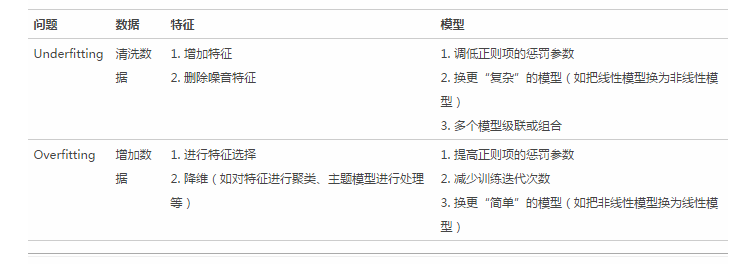
###怎么解決Underfitting和Overfitting問題����?
總結(jié)
綜上所述,機器學(xué)習(xí)解決問題涉及到問題建模��、準備訓(xùn)練數(shù)據(jù)�����、抽取特征��、訓(xùn)練模型和優(yōu)化模型等關(guān)鍵環(huán)節(jié)���,有如下要點:
理解業(yè)務(wù)����,分解業(yè)務(wù)目標��,規(guī)劃模型可預(yù)估的路線圖�����。
數(shù)據(jù):
y數(shù)據(jù)盡可能真實客觀���;
訓(xùn)練集/測試集分布與線上應(yīng)用環(huán)境的數(shù)據(jù)分布盡可能一致�。
特征:
利用Domain Knowledge進行特征抽取和選擇����;
針對不同類型的模型設(shè)計不同的特征。
模型:
針對不同業(yè)務(wù)目標�、不同數(shù)據(jù)和特征,選擇不同的模型���;
如果模型不符合預(yù)期�����,一定檢查一下數(shù)據(jù)���、特征、模型等處理環(huán)節(jié)是否有bug����;
考慮模型Underfitting和Qverfitting,針對性地優(yōu)化。
