目錄
- 一�、需求背景
- 二���、功能描述
- 三��、技術(shù)方案
- 四、登錄豆瓣
- 1.分析豆瓣登錄接口
- 2.代碼實現(xiàn)登錄豆瓣
- 3.保存會話狀態(tài)
- 4.這個Session對象是我們常說的session嗎?
- 五��、爬取影評
- 1.分析豆瓣影評接口
- 2.爬取一條影評數(shù)據(jù)
- 3.影評內(nèi)容提取
- 4.批量爬取
- 六、分析影評
- 七�、總結(jié)
上一篇我們講過Cookie相關(guān)的知識,了解到Cookie是為了交互式web而誕生的���,它主要用于以下三個方面:
- 會話狀態(tài)管理(如用戶登錄狀態(tài)�����、購物車��、游戲分數(shù)或其它需要記錄的信息)
- 個性化設置(如用戶自定義設置、主題等)
- 瀏覽器行為跟蹤(如跟蹤分析用戶行為等)
我們今天就用requests庫來登錄豆瓣然后爬取影評為例子����,用代碼講解下Cookie的會話狀態(tài)管理(登錄)功能。
此教程僅用于學習��,不得商業(yè)獲利���!如有侵害任何公司利益���,請告知刪除!
一�、需求背景
之前豬哥帶大家爬取了優(yōu)酷的彈幕并生成詞云圖片,發(fā)現(xiàn)優(yōu)酷彈幕的質(zhì)量并不高���,有很多介詞和一些無效詞����,比如:哈哈��、啊啊�、這些、那些。����。���。而豆瓣口碑一直不錯�,有些書或者電影的推薦都很不錯,所以我們今天來爬取下豆瓣的影評���,然后生成詞云�,看看效果如何吧!
二�、功能描述
我們使用requests庫登錄豆瓣,然后爬取影評��,最后生成詞云��!
為什么我們之前的案例(京東�����、優(yōu)酷等)中不需要登錄���,而今天爬取豆瓣需要登錄呢�����?那是因為豆瓣在沒有登錄狀態(tài)情況下只允許你查看前200條影評���,之后就需要登錄才能查看�����,這也算是一種反扒手段��!
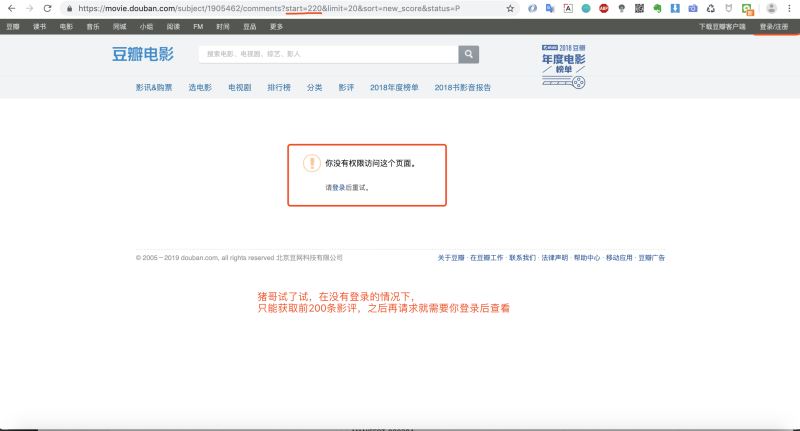
三���、技術(shù)方案
我們看下簡單的技術(shù)方案�����,大致可以分為三部分:
- 分析豆瓣的登錄接口并用requests庫實現(xiàn)登錄并保存cookie
- 分析豆瓣影評接口實現(xiàn)批量抓取數(shù)據(jù)
- 使用詞云做影評數(shù)據(jù)分析
方案確定之后我們就開始實際操作吧!
四�、登錄豆瓣
做爬蟲前我們都是先從瀏覽器開始,使用調(diào)試窗口查看url�。
1.分析豆瓣登錄接口
打開登錄頁面,然后調(diào)出調(diào)試窗口�����,輸入用戶名和密碼�����,點擊登錄�。
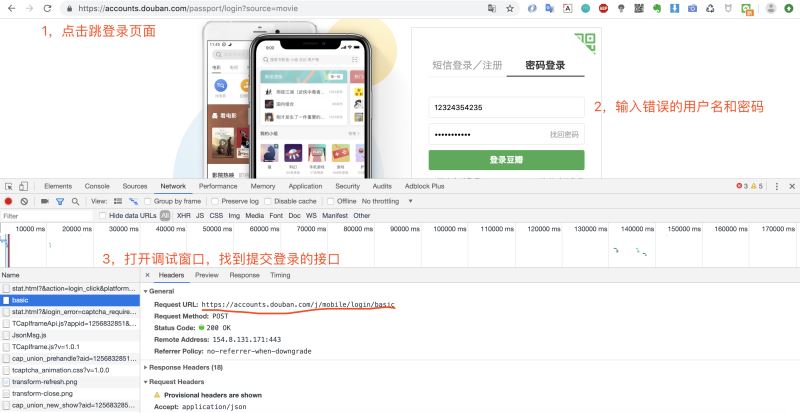
這里豬哥建議輸入錯誤的密碼�����,這樣就不會因為頁面跳轉(zhuǎn)而捕捉不到請求��!上面我們便獲取到登錄請求的URL:https://accounts.douban.com/j/mobile/login/basic
因為是一個POST請求,所以我們還需要看看請求登錄時攜帶的參數(shù),我們將調(diào)試窗口往下拉查看Form Data���。

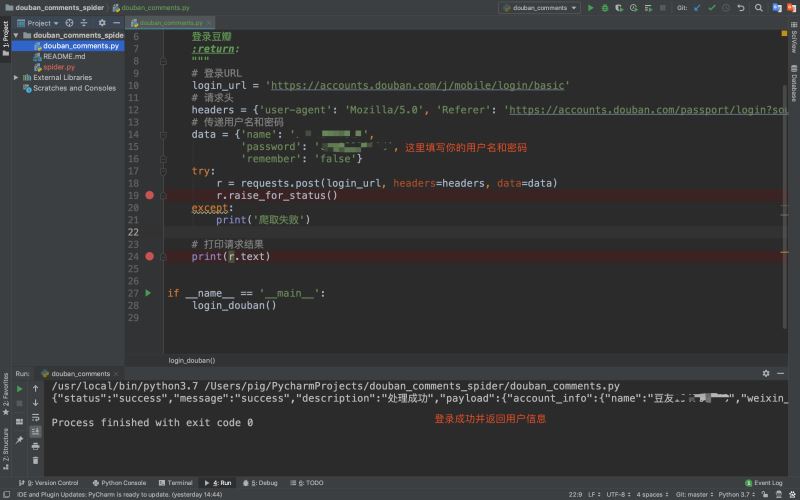
2.代碼實現(xiàn)登錄豆瓣
得到登錄請求URL和參數(shù)后,我們就可以來用requests庫來寫一個登錄功能!
3.保存會話狀態(tài)
上期我們在爬取優(yōu)酷彈幕的時候我們是復制瀏覽器中的Cookie到請求頭中這來來保存會話狀態(tài)�����,但是我們?nèi)绾巫尨a自動保存Cookie呢����?
也許你見過或者使用過urllib庫,它用來保存Cookie的方式如下:
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HttpCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
opener(url)
但是前面我們介紹requests庫的時候就說過:
requests庫是一個基于urllib/3的第三方網(wǎng)絡庫���,它的特點是功能強大��,API優(yōu)雅�。由上圖我們可以看到,對于http客戶端python官方文檔也推薦我們使用requests庫�,實際工作中requests庫也是使用的比較多的庫。
所以今天我們來看看requests庫是如何優(yōu)雅的幫我們自動保存Cookie的���?我們來對代碼做一點微調(diào)�����,使之能自動保存Cookie維持會話狀態(tài)����!
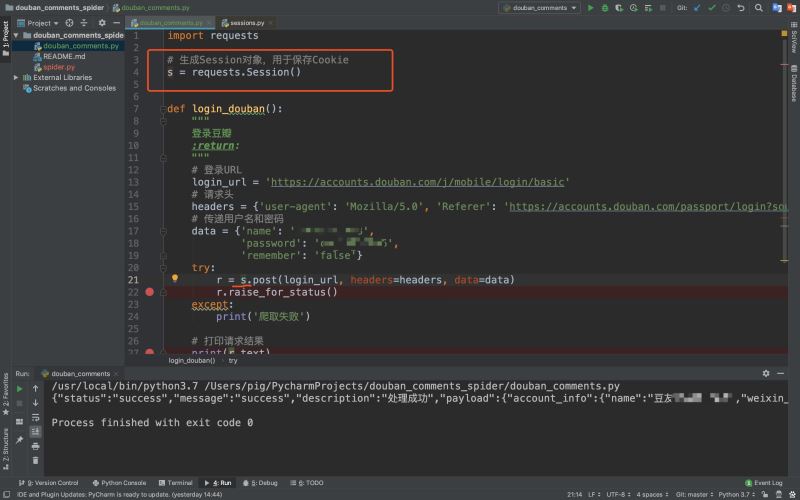
上述代碼中����,我們做了兩處改動:
- 在最上面增加一行
s = requests.Session(),生成Session對象用來保存Cookie
- 發(fā)起請求不再是原來的requests對象�����,而是變成了Session對象
我們可以看到發(fā)起請求的對象變成了session對象�����,它和原來的requests對象發(fā)起請求方式一樣,只不過它每次請求會自動帶上Cookie�����,所以后面我們都用Session對象來發(fā)起請求�����!
4.這個Session對象是我們常說的session嗎����?
講到這里也許有同學會問:requests.Session對象是不是我們常說的session呢?
答案當然不是��,我們常說的session是保存在服務端的���,而requests.Session對象只是一個用于保存Cookie的對象而已,我們可以看看它的源碼介紹
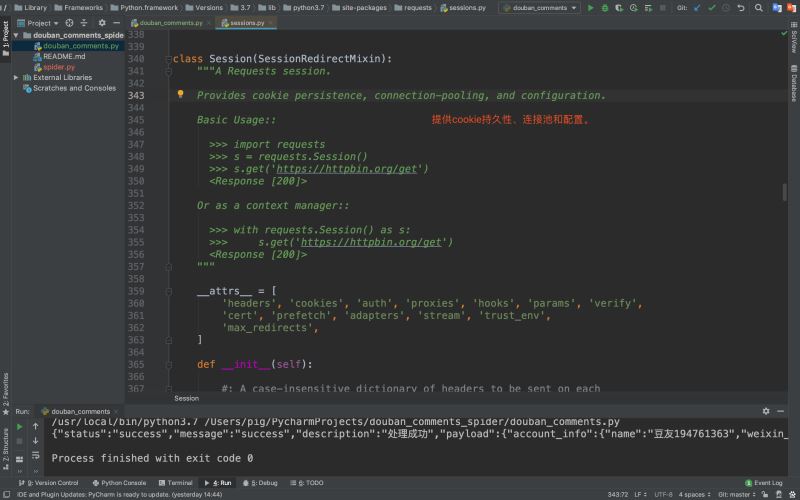
所以大家千萬不要將requests.Session對象與session技術(shù)搞混了�����!
五��、爬取影評
我們實現(xiàn)了登錄和保存會話狀態(tài)之后�����,就可以開始干正事啦!
1.分析豆瓣影評接口
首先在豆瓣中找到自己想要分析的電影���,這里豬哥選擇一部美國電影**《荒野生存》**����,因為這部電影是豬哥心中之最����,沒有之一!
然后下拉找到影評�����,調(diào)出調(diào)試窗口��,找到加載影評的URL
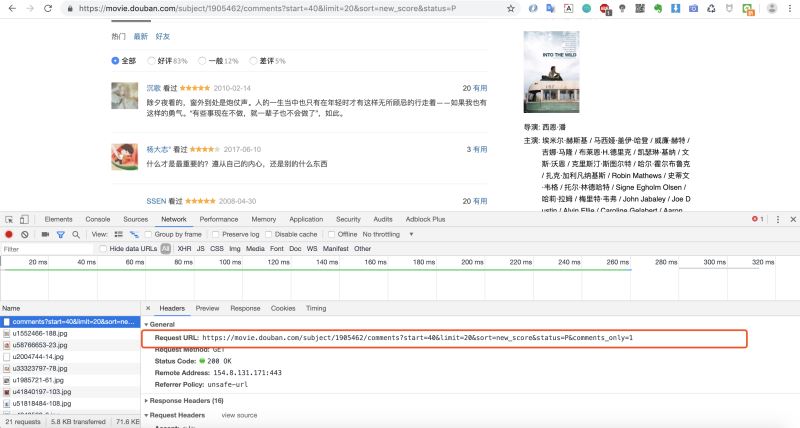
2.爬取一條影評數(shù)據(jù)
但是爬取下來的是一個HTML網(wǎng)頁數(shù)據(jù)�����,我們需要將影評數(shù)據(jù)提取出來
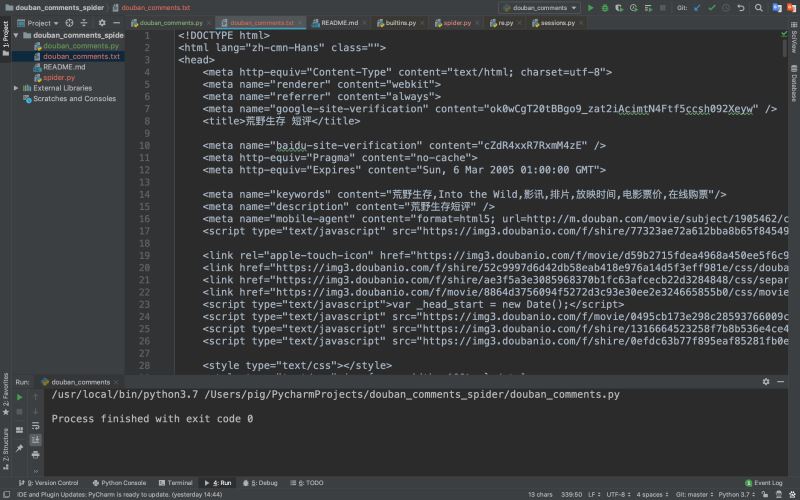
3.影評內(nèi)容提取
上圖中我們可以看到爬取返回的是html�����,而影評數(shù)據(jù)便是嵌套在html標簽中,如何提取影評內(nèi)容呢����?
這里我們使用正則表達式來匹配想要的標簽內(nèi)容,當然也有更高級的提取方法����,比如使用某些庫(比如bs4、xpath等)去解析html提取內(nèi)容�,而且使用庫效率也比較高,但這是我們后面的內(nèi)容�,我們今天就用正則來匹配!
我們先來分析下返回html 的網(wǎng)頁結(jié)構(gòu)
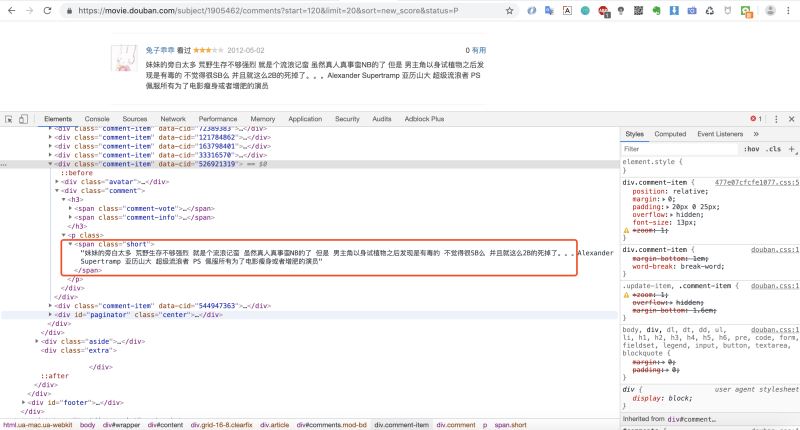
我們發(fā)現(xiàn)影評內(nèi)容都是在span class="short">/span>這個標簽里�����,那我們 就可以寫正則來匹配這個標簽里的內(nèi)容啦�!
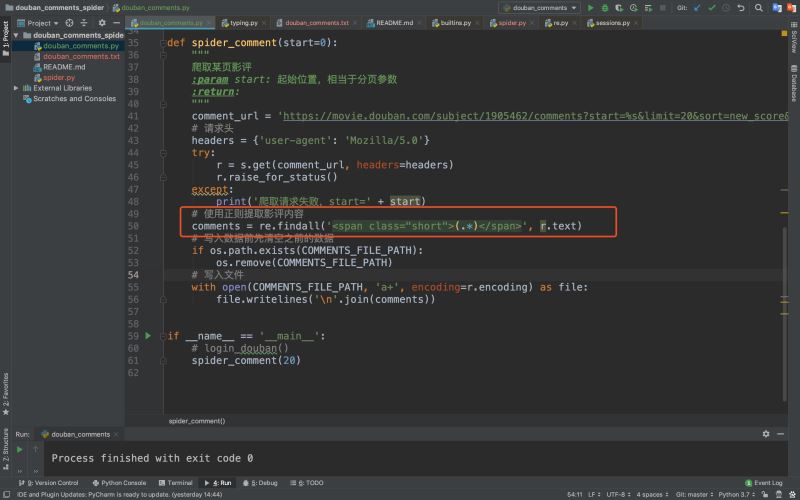
檢查下提取的內(nèi)容
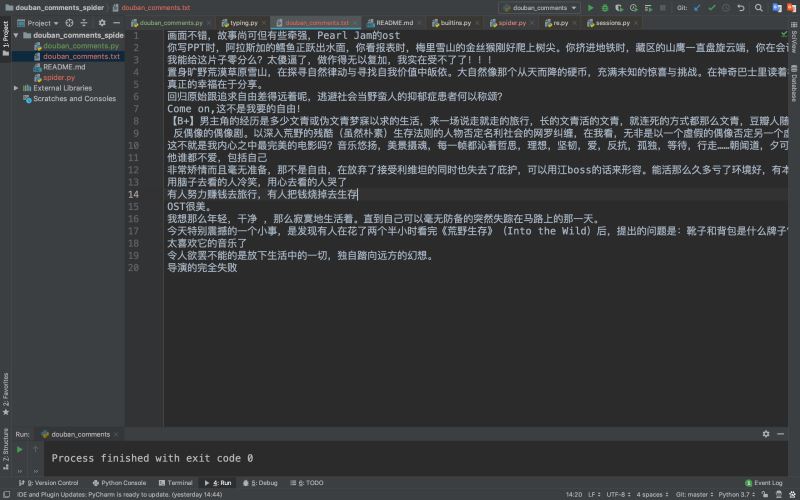
4.批量爬取
我們爬取、提取����、保存完一條數(shù)據(jù)之后�����,我們來批量爬取一下。根據(jù)前面幾次爬取的經(jīng)驗�����,我們知道批量爬取的關(guān)鍵在于找到分頁參數(shù)�����,我們可以很快發(fā)現(xiàn)URL中有一個start參數(shù)便是控制分頁的參數(shù)�����。
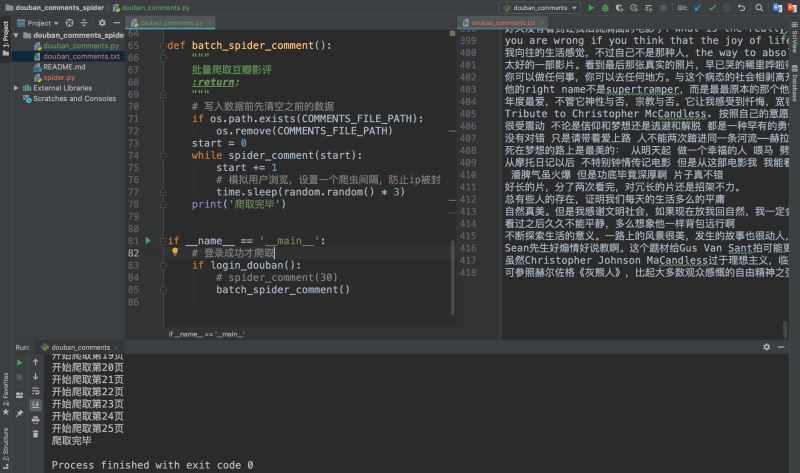
這里只爬取了25頁就爬完���,我們可以去瀏覽器中驗證一下����,是不是真的只有25頁�,豬哥驗證過確實只有25頁!
六��、分析影評
數(shù)據(jù)抓取下來之后�,我們就來使用詞云分析一下這部電影吧!
基于使用詞云分析的案例前面已經(jīng)講過兩個了,所以豬哥只會簡單的講解一下��!
1.使用結(jié)巴分詞
因為我們下載的影評是一段一段的文字�,而我們做的詞云是統(tǒng)計單詞出現(xiàn)的次數(shù),所以需要先分詞��!
2.使用詞云分析
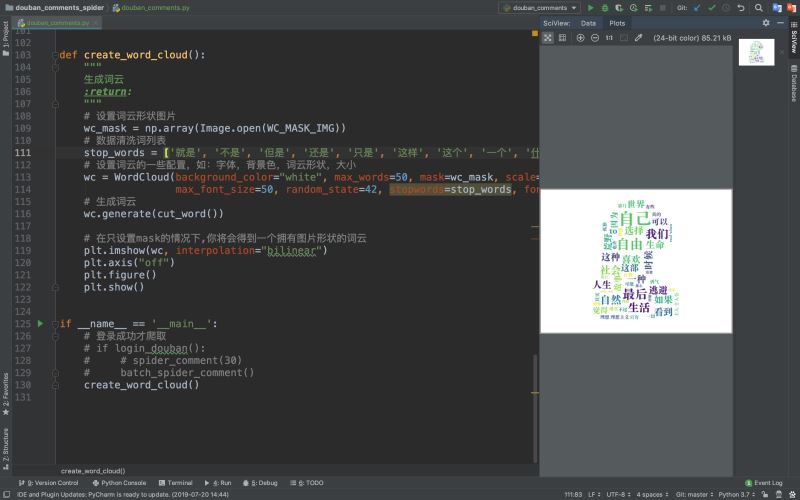
最終成果:

從這些詞中我們可以知道這是關(guān)于一部關(guān)于追尋自我與現(xiàn)實生活的電影�����,豬哥裂墻推薦?����。�。?/p>
七�����、總結(jié)
今天我們以爬取豆瓣為例子���,學到了不少的東西����,來總結(jié)一下:
- 學習如何使用requests庫發(fā)起POST請求
- 學習了如何使用requests庫登錄網(wǎng)站
- 學習了如何使用requests庫的Session對象保持會話狀態(tài)
- 學習了如何使用正則表達式提取網(wǎng)頁標簽中的內(nèi)容
鑒于篇幅有限�����,爬蟲過程中遇到的很多細節(jié)和技巧并沒有完全寫出來����,所以希望大家能自己動手實踐
源碼地址:https://github.com/pig6/douban_comments_spider
到此這篇關(guān)于詳解如何用Python登錄豆瓣并爬取影評的文章就介紹到這了,更多相關(guān)Python爬取影評內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 詳解如何用Python模擬登錄淘寶
- python模擬登陸網(wǎng)站的示例
- selenium攜帶cookies模擬登陸CSDN的實現(xiàn)
- python 模擬登陸github的示例
- python requests模擬登陸github的實現(xiàn)方法
- 詳解python項目實戰(zhàn):模擬登陸CSDN
- python模擬登陸,用session維持回話的實例
