目錄
- 前言
- 寫在前面
- 1.什么是機器學習?
- 1.1 監(jiān)督學習
- 1.2無監(jiān)督學習
- 2.Python中的機器學習
- 3.必須環(huán)境安裝
- 總結(jié)
前言
每一次變革都由技術(shù)驅(qū)動��?��?v觀人類歷史�,上古時代�����,人類從采集狩獵社會����,進化為農(nóng)業(yè)社會;由農(nóng)業(yè)社會進入到工業(yè)社會;從工業(yè)社會到現(xiàn)在信息社會����。每一次變革,都由新技術(shù)引導�。
在歷次的技術(shù)革命中,一個人�����、一家企業(yè)����,甚至一個國家,可以選擇的道路只有兩條:要么加入時代的變革��,勇立潮頭�����;要么徘徊觀望����,抱憾終生。
要想成為時代弄潮兒����,就要積極擁抱這次智能變革,就要掌握在未來社會不會被淘汰的技能����,強大自己,為社會�、為國家貢獻自己的力量。而在以大數(shù)據(jù)為基石的智能社會���,我們就要積極掌握前沿技術(shù)����,機器學習就是信息時代人工智能領(lǐng)域核心技術(shù)之一��。
像個優(yōu)秀的工程師一樣使用機器學習��,而不要像個機器學習專家一樣使用機器學習方法�����。
——Google
寫在前面
機器學習中算法眾多��,原理復雜���,需要大量知識儲備才能真正理解���,也不需要完全理解����,在今后的學習過程中逐漸積累�����,自然會逐漸掌握�����。因此本系列不會著重介紹算法原理�,而側(cè)重于如何“像一個優(yōu)秀的工程師一樣使用機器學習”。
1.什么是機器學習�?
機器學習(Machine Learning,ML)是一門多領(lǐng)域的交叉學科�����,涉及概率論�、統(tǒng)計學、線性代數(shù)���、算法等多門學科���。它專門研究如何使計算機模擬和學習人的行為,以獲取新的知識和技能�����,重新組織已有的知識結(jié)構(gòu)使之不斷完善自身的性能��,
機器學習擁有十分廣泛的應用��,例如:數(shù)據(jù)挖掘����、計算機視覺、自然語言處理�����、生物特征識別�、搜索引擎、醫(yī)學診斷�����、檢測信用卡欺詐、證券市場分析����、DNA序列測序、語音和手寫識別等�。
機器學習算法可分為兩大類:監(jiān)督學習和無監(jiān)督學習。
下圖是機器學習相關(guān)概念的思維導圖:

1.1 監(jiān)督學習
監(jiān)督學習即在機器學習過程中提供對錯指示���。一般是在數(shù)據(jù)組中包含最終結(jié)果(0,1)�,通過最終結(jié)果來讓機器自己減小誤差��。
這一類學習主要應用于分類和回歸(Regression Classify)��。監(jiān)督學習從給定的訓練數(shù)據(jù)集中學習出一個目標函數(shù)�,當新的數(shù)據(jù)到來時,可以根據(jù)這個函數(shù)預測結(jié)果��。監(jiān)督學習的訓練集要求包括輸入和輸出(只要有標簽的均可認為是監(jiān)督學習)�����,也可以說包括特征和目標����,訓練集中的目標是認為標注的�。
常見的監(jiān)督學習算法包括回歸分析和統(tǒng)計分類���。
1.2無監(jiān)督學習
無監(jiān)督學習又稱為歸納性學習(Clustering)�,利用K方式(KMean)建立中心(Centriole),通過循環(huán)和遞減運算(IterationDescent)來減小誤差��,達到分類的目的����。
2.Python中的機器學習
本文將通過項目來介紹基于Python的生態(tài)環(huán)境如何完成機器學習的相關(guān)工作�����。
利用機器學習的預測模型來解決問題共有六個基本步驟:
- 定義問題:研究和提煉問題的特征�����,以便我們采用相應的思路和方法來解決問題�����。
- 數(shù)據(jù)理解:通過統(tǒng)計性描述和可視化方法來分析現(xiàn)有的數(shù)據(jù)���。
- 數(shù)據(jù)準備:對數(shù)據(jù)進行格式化�,以便構(gòu)建預測模型。
- 評估算法:利用測試集來評估算法模型���,并選取一部分代表數(shù)據(jù)進行分析��,以改善模型���。
- 優(yōu)化模型:通過調(diào)參和集成算法來提升結(jié)果的準確度。
- 結(jié)果部署:完成模型��,并執(zhí)行模型來預測結(jié)果和展示�。
這也是本文寫作的順序。閱讀完本文���,讀者能夠基本了解機器學習的基本步驟�����、實現(xiàn)方法���,以便在自己的項目中利用機器學習來解決問題。
3.必須環(huán)境安裝
機器學習需要用到的相關(guān)模塊包括SciPy�����,NumPy,Matplotlib����,Pandas,Scikit-learn�。
SciPy是在數(shù)學運算、科學和工程學方面被廣泛應用的Python類庫�。它包括統(tǒng)計、優(yōu)化��、整合�、線性代數(shù)����、傅里葉變換、信號和圖像處理�����、常微分方程求解器等�����,被廣泛運用在機器學習的項目中。
NumPy(Numerical Python) 是 Python 語言的一個擴展程序庫��,支持高維度數(shù)組與矩陣運算����,此外也針對數(shù)組運算提供大量的數(shù)學函數(shù)庫。
Matplotlib是Python中最著名的2D繪圖庫��,十分適合交互式地繪圖����,也可方便地將它作為繪圖控件,嵌入GUI應用程序中��。
Pandas 是Python的核心數(shù)據(jù)分析支持庫�,提供了快速、靈活�����、明確的數(shù)據(jù)結(jié)構(gòu)�����,旨在簡單��、直觀地處理關(guān)系型、標記型數(shù)據(jù)�。
Scikit-learn (sklearn) 是基于 Python 語言的機器學習工具,可以實現(xiàn)數(shù)據(jù)預處理�、分類、回歸�����、降維�、模型選擇等常用的機器學習算法。
Anacodna安裝
Anaconda 個人版是一個免費����、易于安裝的包管理器、環(huán)境管理器和 Python 發(fā)行版����,包含 1,500 多個開源包�����,并提供免費社區(qū)支持��。其中的虛擬環(huán)境真的非常Nice���,可以方便地針對不同項目安裝不同模塊���。
安裝Anaconda時會自動地安裝機器學習需要地所有庫���,無需再通過Pip逐個安裝。
Anaconda的安裝十分簡單����,但Anaconda官網(wǎng)安裝非常慢,推薦到清華鏡像下載:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
next
I Agree
Just Me
更改安裝路徑到其他盤
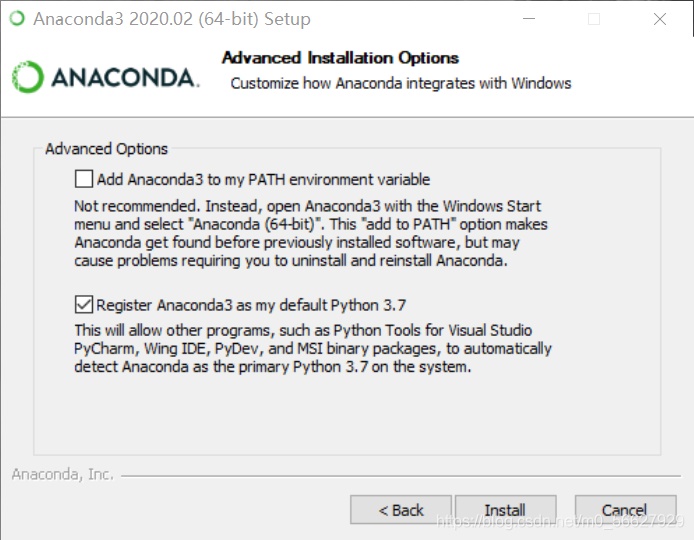
勾選Register Anaconda3 as my default Python3.7�,不推薦勾選第一個
點擊Install
安裝完成之后可以使用以下命令檢驗是否安裝成功:
import scipy
import numpy
import matplotlib
import pandas
import sklearn
print('scipy:{}'.format(scipy.__version__))
print('numpy:{}'.format(numpy.__version__))
print('matplotlib:{}'.format(matplotlib.__version__))
print('pandas:{}'.format(pandas.__version__))
print('sklearn:{}'.format(sklearn.__version__))
結(jié)果如下:
scipy:1.4.1
numpy:1.21.0
matplotlib:3.4.2
pandas:1.0.1
sklearn:0.22.1
總結(jié)
到此為止,我們已經(jīng)了解了機器學習的基本概念并完成了環(huán)境的安裝�,接下來將完善數(shù)據(jù)理解、數(shù)據(jù)準備����、選擇模型、優(yōu)化模型��、結(jié)果部署以及項目實戰(zhàn)����。
到此這篇關(guān)于Python機器學習入門(一)序章的文章就介紹到這了,更多相關(guān)Python機器學習內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Python機器學習入門(二)之Python數(shù)據(jù)理解
- Python機器學習入門(三)之Python數(shù)據(jù)準備
- Python機器學習入門(四)之Python選擇模型
- Python機器學習入門(五)之Python算法審查
- Python機器學習入門(六)之Python優(yōu)化模型
- python機器學習高數(shù)篇之函數(shù)極限與導數(shù)
