交叉統(tǒng)計是什么統(tǒng)計方式?請具體告訴我統(tǒng)計表的制作方法和閱讀方法。
Answer
交叉統(tǒng)計就是從所給數(shù)據(jù)中提取兩個以上的關(guān)注項目���,把各項目放在表的列和行上進行統(tǒng)計的方法�����。交叉統(tǒng)計的目的是為了獲得簡單統(tǒng)計中掌握不了的屬性或者問題之間的深層洞察��。
解起
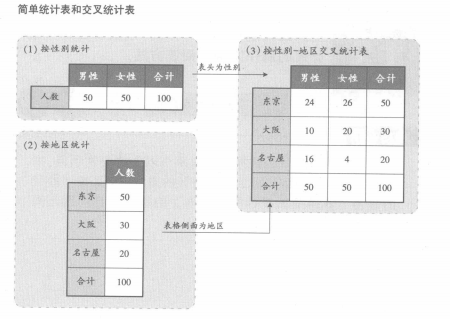
■什么是交叉統(tǒng)計���?
在調(diào)查中,對回答某個問題的人或者數(shù)據(jù)庫中存在的數(shù)據(jù)次數(shù)和比例����,用單個項目的觀點進行統(tǒng)計的,叫做簡單統(tǒng)計�����。與此相對�,交叉統(tǒng)計是指在表頭和表格側(cè)部寫入了屬性項目或者問題項目,進行項目次數(shù)和比例的復雜統(tǒng)計����。簡單統(tǒng)計只能統(tǒng)計問卷調(diào)查中的性別或地區(qū)等基礎(chǔ)的項目�,而通過交叉統(tǒng)計�,可以知道與屬性欄相關(guān)的問題等,從而獲得更加深刻的認知����。
交叉統(tǒng)計可用表格計算軟件進行簡單的制作����。最常見的表格計算軟件是Microsoft的Excel,利用數(shù)據(jù)透視表(PivotTable)"功能,通過在表格的頂部��、側(cè)部的自由插入����,就可以更改數(shù)據(jù)的統(tǒng)計方法。
■交叉統(tǒng)計表的讀取方法
通過交叉統(tǒng)計表��,可以讀取項目之間的關(guān)聯(lián)性��。如果各項目之間的某處存在較大差異,就說明那里有某些潛在原因���。這個差異是營銷
策略實施的重要依據(jù)�,所以從交叉統(tǒng)計表中讀出差異非常重要�����。要判斷有無差異,正確檢驗的統(tǒng)計技術(shù)是必需的,此外�,能夠正確理解并利用檢驗也很重要。在這里我們向大家介紹一種簡單易懂的找到差異的方法�。
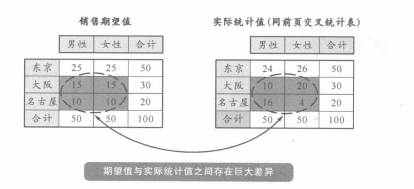
這種方法就是找出期望值和統(tǒng)計值差距很大的欄目。這里說的期望值是指在進行簡單統(tǒng)計時得出的和各項目之間完全沒有關(guān)聯(lián)的統(tǒng)計數(shù)值�����。例如:在上圖的簡單統(tǒng)計表和交叉統(tǒng)計表中��,可知東京的男女人數(shù)合計為50��。在簡單統(tǒng)計表里���,男女比例是1:1,那么在交叉統(tǒng)計表中�����,男女比例的期望值也就是1:1,東京合計的50人當中��,男女應該各為25人�����。再看一下交叉統(tǒng)計表中的實際統(tǒng)計值����,是男24人,女26人,這樣我們就知道���,統(tǒng)計值和期望值沒有多大差異��。
在大阪和名古屋,通過同樣的計算,發(fā)現(xiàn)期望值和實際統(tǒng)計值有很大的差異�。名古屋女性這一欄尤為顯著,期望值是10人���,而實際統(tǒng)計值只有4人,這樣我們就知道期望值是實際值的2.5倍�����。像這樣有很大差異的項目內(nèi)容�,在評價和解釋交叉統(tǒng)計表的時候就非常引人注目���。負責分析的人員將把產(chǎn)生這種差異的原因也包括在內(nèi)���,對統(tǒng)計結(jié)果進伸價����、分析�����。
■多重交叉統(tǒng)計的注意事項
初學交叉統(tǒng)計的人都很容易產(chǎn)生過度依賴���。初學者為了更加深刻地洞察各項目����,往往過多地使用3重�����、4重甚至更多重交叉表;但隨著多重度的增多,每個欄里所能容納的數(shù)據(jù)度數(shù)也會變少�����。如果每欄的數(shù)據(jù)度數(shù)比參數(shù)小很多的話,這個數(shù)值就會變得沒有多少說服力����,這一點希望大家注意���。
Answer
所謂多變量解析就是統(tǒng)計分析多個變量的數(shù)據(jù)后��,明確變量間的關(guān)系����,發(fā)現(xiàn)有效信息的手法的總稱。
■什么是多變量解析�?
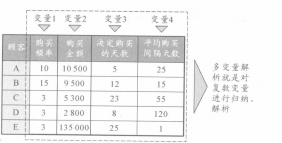
在了解多變量解析前,有必要先了解一下什么是變量�。例如下面是某個店鋪制作的關(guān)于每個顧客購物情況數(shù)據(jù)的表格���。購買頻率���、購買金額等項目中,由于顧客不同對應的數(shù)據(jù)也不同�����。在統(tǒng)計學中�����,值隨著樣本(這里指顧客)變化而變化的項目就叫做變量(或者叫變數(shù))�。
所謂多變量解析,并不是把多個變量細分化,而是同時進行分析,然后得到有效的信息��。
■多變量解析的特征
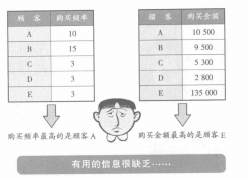
既然有多變量解析,當然也就有一個變量或是兩個變量的解析����。我們把變量是一個的叫做單變量解析或者一變量解析,把變量是兩個的叫做二變量解析�。用一變量解析和二變量解析,可以通過查頻率分布和散布圖得到一些信息�����。這些方法非常簡單,也比較容易理解�����,但另一方面因為變量太少��,只能看到實物的一個或兩個方面���,得出的結(jié)果�,一般沒有什么意義。例如上文所列舉的顧客數(shù)據(jù)�����,如果一個一個變量地看��,購買頻率最高的是A.購買金額最高的是E���。只能得到這樣的數(shù)據(jù)�����。
多變量解析則可以同時分析多個變量之間的關(guān)系��,這樣�,我們就可以知道某個變量對其他變量有什么影響����。例如通過多變量解析我們有可能找出研究對象的選定和研究時機的選定之間存在的關(guān)系����。
運用多變量解析,專業(yè)的統(tǒng)計知識是必要的。以前,由于計算量龐大�,要得到計算結(jié)果比較困難�����,但隨著計算機的發(fā)展和多變量解析軟件的改良,現(xiàn)在的企業(yè)和個人在運用多變量解析時已經(jīng)容易多了����。
根據(jù)多變量解析的分析目的和變量的種類不同��,有很多種處理方法,所得到的結(jié)果也不同�����。如果沒有正確的知識就去運用這些方法,會導致意想不到的錯誤�����,甚至可能只得到一些錯誤的答案���。因此,利用多變量解析,正確理解各種方法很重要����。
構(gòu)建顧客行動模式��,制作反應率高的名單,具體應該利用哪些數(shù)據(jù)���,采取哪些步驟��?
Answer
利用顧客屬性����、購買記錄��、過去的促銷信息等構(gòu)建顧客行動模式��,以此模式為基礎(chǔ)計算出各顧客的行動概率�。
■制作名單的步驟
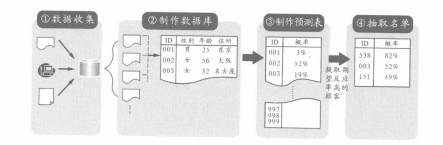
顧客行動模式是企業(yè)基于顧客屬性、購買行為等過去的信息做成的��、預測顧客將來行動方式的數(shù)學公式o以這個數(shù)學公式為基礎(chǔ)�����,算出顧客(以及潛在顧客)的期望反應率�����,然后再抽取期望反應率高的顧客制作成電話外呼對象的顧客名單�����。大致來說��,制作出期望反應率高的名單需要以下4個步驟:
①數(shù)據(jù)收集
首先,將企業(yè)內(nèi)分散的數(shù)據(jù)匯集到一處����。企業(yè)各操作現(xiàn)場獲得的與顧客相關(guān)的所有信息都有可能成為構(gòu)建顧客行動模式的原始數(shù)據(jù)o如注冊積分卡時登記的性別、出生日期等顧客屬性信息��,記錄了顧客在何時以何種價格購買了什么商品等的購買記錄信息�����,發(fā)送電子雜志����、直郵廣告等方面的促銷信息等,都可以作為原始數(shù)據(jù)����。
②制作數(shù)據(jù)庫
接著,把多個原始數(shù)據(jù)匯總到一張表上做成數(shù)據(jù)庫��。首先要設計使用哪個原始數(shù)據(jù)作為某列項目來制作數(shù)據(jù)庫����,然后進行數(shù)據(jù)清理����、姓名匯總等����,以一個顧客一條記錄的匯集形式加以總結(jié)。在數(shù)據(jù)庫的項目中���,涵蓋了從顧客屬性到平均購買額�、單位時間的購買次數(shù)�����、平均購買件數(shù)���、購買間隔�、直郵發(fā)送次數(shù)��、直郵反應率(攜帶在直郵里的優(yōu)惠券的使用率)等信息����。制作數(shù)據(jù)庫的具體情況��,將在FAQ16中詳細說明。
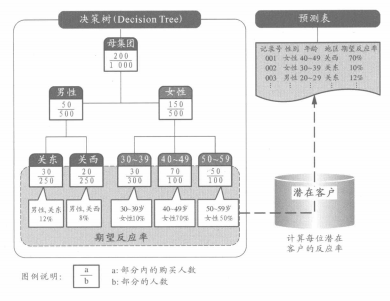
③制作預測表
預測表是顧客將發(fā)生某種行動的概率(期望反應率)一覽表�����。要制作預測表���,需先使用統(tǒng)計的分析方法構(gòu)建顧客行動模式�����,以該模式為基礎(chǔ)����,通過打分來算出每個顧客的期望反應率(預測值)��。較容易理解的例子就是決策樹"(DecisionTree)�����。決策樹是通過樹形圖來表示數(shù)據(jù)項目間的因果關(guān)系,同時計算出不同屬性顧客的期望反應率�����。制作顧客行動模式時,一般運用市場上銷售的數(shù)據(jù)挖掘軟件�,如Market Switch公司銷售的TrueforTransactionModeling(TTM)等。
④抽取名單
從預測表中抽取行動概率高的顧客,制作反應率高的顧客名單��。抽取的顧客數(shù)以業(yè)務規(guī)模�����、打電話費用等為基礎(chǔ)來設定��。
制作用于構(gòu)建顧客行動模式的數(shù)據(jù)庫����,需要做哪些工作?
Answer
每個顧客都有一份檔案���,這就是用于構(gòu)建顧客行動模式的數(shù)據(jù)�。但其中一連串的處理不但復雜且繁瑣���,要花費很多時間��。
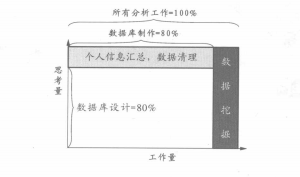
■數(shù)據(jù)庫制作占整個分析工作量的80%
為了制作用于構(gòu)建顧客行動模式的數(shù)據(jù)庫���,首先要明確其利用目的,在此基礎(chǔ)上再進行設計工作;然后根據(jù)設計的內(nèi)容進行數(shù)據(jù)清理及個人���、家庭信息匯總等。
通過這樣的一個過程���,整理出一人一行的一覽表�,制成構(gòu)建顧客行動模式可使用的數(shù)據(jù)庫�。這一系列處理會相當麻煩��,因此需要花費很多時間��。大體而言�����,數(shù)據(jù)庫的制作要占到所有分析工作80%的工作量����。
■數(shù)據(jù)庫設計占整個數(shù)據(jù)庫制作思考量的80%
數(shù)據(jù)庫的設計是從已有的數(shù)據(jù)中,找出構(gòu)建顧客行動模式所必需的信息����。該數(shù)據(jù)庫中的數(shù)據(jù)是顧客行動模式的輸入數(shù)據(jù),因此會直接影響模式的精度�,所以數(shù)據(jù)庫設計是所有分析工作中最重要的�。要對數(shù)據(jù)進行細查��,就應清楚地將能夠使用的數(shù)據(jù)和不能夠使用的數(shù)據(jù)分開��。對于這項工作����,不僅需要有縝密的思考能力,還要有在過去的經(jīng)驗及事物的基礎(chǔ)上進行類推的能力�����?�?梢哉f在數(shù)據(jù)庫的做成中數(shù)據(jù)庫的設計就需要占用其80%的思考量(見下圖)�。
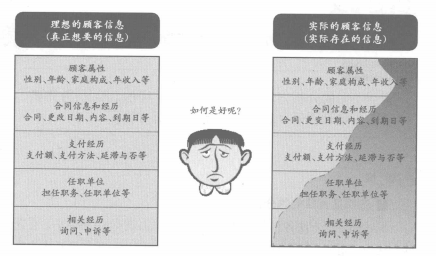
■需要的數(shù)據(jù)并不一定全部都有
數(shù)據(jù)庫設計時,要找到構(gòu)建顧客行動模式所必需的數(shù)據(jù),但是想要的信息并不一定全都在自己公司的數(shù)據(jù)儲備中�。如果要制作精細的顧客行動模式,從顧客屬性到對應的顧客履歷,所有與顧客相關(guān)的數(shù)據(jù)都是需要的。但事實是,不要說收集所有的數(shù)據(jù)�����,就連收集到的數(shù)據(jù)也不一定完整�����。而且,收集到的數(shù)據(jù)也并不都可以直接用于顧客行動模式的構(gòu)建�。例如數(shù)據(jù)的分布范圍過廣,或者牽連的其他數(shù)據(jù)過多時,就難以得到正確的分析結(jié)果���,或者無法充分把握其結(jié)果��。
為了解決此類問題�,需把收集到的數(shù)據(jù)進行適當加工��,轉(zhuǎn)換成對構(gòu)建顧客行動模式有幫助的信息���。例如,將郵政編碼改為行政區(qū)域和地域名稱,對購買履歷中的購買次數(shù)、累計金額�����、間隔等變量做一個說明等����。對于變量的說明需要經(jīng)驗和靈感,因此數(shù)據(jù)挖掘被公認為是一種專業(yè)技能��。
■數(shù)據(jù)庫和個人信息匯總處理
即使作出了變量說明,也還沒有完成構(gòu)建顧客行動模式的數(shù)據(jù)庫��。還有必要進行數(shù)據(jù)清理和個人信息匯總。
數(shù)據(jù)清理是對信息內(nèi)容進行大小寫��、全半角的統(tǒng)一,數(shù)據(jù)類型的統(tǒng)一,對空格(Null)等缺損值插入文字列實施處理,并用數(shù)據(jù)清理工具調(diào)整為可處理狀態(tài)�����。如果一個項@的缺失信息太多�����,那么這個項目將從模式的構(gòu)建內(nèi)容中去除�����。
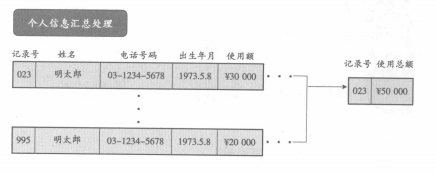
個人信息匯總是對數(shù)據(jù)庫中存在的顧客信息進行統(tǒng)一化處理�,把住所、姓名�����、電話號碼����、出生年月等作為關(guān)鍵項目,將同一顧客的多條記錄匯總成一條記錄。屆時�����,再利用合算總額等方法,整合關(guān)鍵項目以外的信息����。對于家庭,也存在統(tǒng)一化的必要,可以用同樣的方法實行家庭信息匯總。
對在電話外呼的戰(zhàn)略立案階段中經(jīng)常使用的幾種分析方法���,應該怎樣選擇��?
分析方法的說明經(jīng)營
Answer
根據(jù)不同的分析方法�����,導出的結(jié)果是不同的。因此���,首先要做的事情是明確目的,然后再選擇分析方法�����。
解說
■選擇適合目的的分析方法
統(tǒng)計的分析方法各種各樣,僅應用于營銷的,就有50種左右�。在這些方法中,選擇一個適合的并非易事。根據(jù)不同目的�����,我們列舉代表性的幾種方法如下�。
■幾種分析方法的簡要說明
①頻率分布表(簡單統(tǒng)計表)將數(shù)據(jù)分成幾個組,對各個組數(shù)據(jù)的數(shù)量進行統(tǒng)計��。這些組被稱做類別,數(shù)據(jù)的數(shù)量被稱做頻率�,可以用來把握整體數(shù)據(jù)的傾向。
②交叉統(tǒng)計表是用來把握不同屬性間數(shù)值關(guān)系的方法��。詳見FAQ13�。
③時序列分析根據(jù)每月獲得客戶數(shù)等的時序列���,每經(jīng)過一段時間,分析數(shù)據(jù)變化的方法�。在時序列分析中,觀測因時間變化而產(chǎn)生的數(shù)據(jù)趨向變化��,根據(jù)得出的數(shù)字來預測將來。
④關(guān)聯(lián)分析法分析顧客同時所購商品的方法����。也稱作購物籃(MarketBasket)分析法,是通過分析銷售數(shù)據(jù)中的購買信息�,找出交叉銷售可能性較高的商品的分析方法。從分析結(jié)果來看,尿布和啤酒是很有名的例子�����。
⑤數(shù)群分析法是將整體性的數(shù)據(jù)分割成幾個組的分析方法,也就是將有相似傾向的數(shù)據(jù)加以分類��,進行使用��。因為被分割的每一個組的數(shù)據(jù)都被稱做數(shù)群,所以這個分析方法叫做數(shù)群分析法�。
⑥判別分析法將存在的數(shù)據(jù)進行是非判斷或者有無區(qū)分的分析方法。判定顧客會不會購買商品,是否是優(yōu)質(zhì)顧客等����,總之是用來明確辨別是與否的分析法。
⑦決策樹是將數(shù)據(jù)項目的因果關(guān)系用樹狀圖形分類的分析法(詳見FAQ15),����。因為是基于某種規(guī)則來分類的,所以能比較容易地理解被分類的優(yōu)質(zhì)顧客群或是預備解約顧客群所具有的特征�。
周四和周五的傍晚��,把尿布和啤酒放在一起賣�?�!
這是美國某個超級市場發(fā)生的事。事情是這樣的��,新上任的賣場負責人在觀察消費者的行為時��,感覺顧客好像把什么東西放在一起購買了,于是這位負責人把過去的銷售記錄也分析了一下����。得出的結(jié)果怎樣呢?竟然是啤酒和尿布兩個都很暢銷。當人們半信半疑地把啤酒和尿布擺放在一起時,的確是意想不到地賣得很好����。特別是在周四和周五的傍晚,非常暢銷����。后來才知道,原來是媽媽們把買尿布的任務交給了下班回家的爸爸們,尤其是在周四和周五��,這些爸爸們就會順便把啤酒也買回來,準備周末喝��。
對這件事的評價眾說紛紜�。這是美國哪個超市的事啊����,是真的嗎�����?實際上這是關(guān)聯(lián)分析的著名事例�����,在營銷界廣為流傳�。在日本也有很多像襪子和醫(yī)療保險一起賣的例子,所以這并不是簡單虛構(gòu)的故事���。