初期架構選型
在2010年10月真正開始動手做知乎這個產品時�����,包含李申申在內��,最初只有兩位工程師;到2010年12月份上線時,工程師是四個。
知乎的主力開發(fā)語言是Python。因為Python簡單且強大����,能夠快速上手����,開發(fā)效率高�,而且社區(qū)活躍�����,團隊成員也比較喜歡��。
知乎使用的是Tornado框架�。因為它支持異步,很適合做實時comet應用��,而且簡單輕量�����,學習成本低�,再就是有FriendFeed 的成熟案例,Facebook 的社區(qū)支持���。知乎的產品有個特性���,就是希望跟瀏覽器端建立一個長連接�����,便于實時推送Feed和通知,所以Tornado比較合適�����。
最初整個團隊的精力全部放在產品功能的開發(fā)上,而其他方面�����,基本上能節(jié)約時間����、能省的都用最簡單的方法來解決���,當然這在后期也帶來了一些問題。
最初的想法是用云主機�,節(jié)省成本����。知乎的第一臺服務器是512MB內存的Linode主機。但是網站上線后�����,內測受歡迎程度超出預期���,很多用戶反饋網站很慢���?���?鐕W絡延遲比想象的要大����,特別是國內的網絡不均衡,全國各地用戶訪問的情況都不太一樣�����。這個問題��,再加上當時要做域名備案�����,知乎又回到了自己買機器找機房的老路上。
買了機器���、找了機房之后又遇到了新的問題�����,服務經常宕掉。當時服務商的機器內存總是出問題���,動不動就重啟����。終于有一次機器宕掉起不來了,這時知乎就做了Web和數據庫的高可用�。創(chuàng)業(yè)就是這樣一個情況,永遠不知道明早醒來的時候會面臨什么樣的問題�。
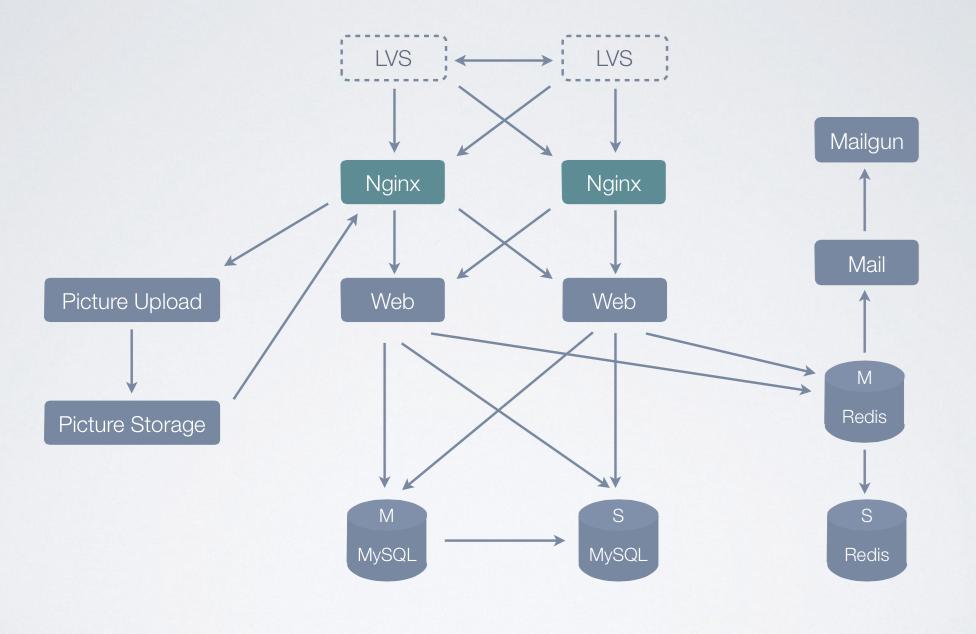
這是當時那個階段的架構圖,Web和數據庫都做了主從��。當時的圖片服務托管在又拍云上��。 除了主從���,為了性能更好還做了讀寫分離����。為解決同步問題�����,又添加了一個服務器來跑離線腳本�����,避免對線上服務造成響應延遲�。另外,為改進內網的吞吐量延遲���, 還更換了設備����,使整個內網的吞吐量翻了20倍。
在2011年上半年時�,知乎對Redis已經很依賴。除了最開始的隊列���、搜索在用,后來像Cache也開始使用����,單機存儲成為瓶頸,所以引入了分片����,同時做了一致性。
知乎團隊是一個很相信工具的團隊��,相信工具可以提升效率�。工具其實是一個過程,工具并沒有所謂的最好的工具����,只有最適合的工具。而且它是在整個過程中,隨著整個狀態(tài)的變化�、環(huán)境的變化在不斷發(fā)生變化的。知乎自己開發(fā)或使用過的工具包括Profiling(函數級追蹤請求���,分析調優(yōu))��、Werkzeug(方便調試的工具)���、Puppet(配置管理)和Shipit(一鍵上線或回滾)等。
日志系統
知乎最初是邀請制的��,2011年下半年���,知乎上線了申請注冊�,沒有邀請碼的用戶也可以通過填寫一些資料申請注冊知乎���。用戶量又上了一個臺階�,這時就有了一些發(fā)廣告的賬戶�����,需要掃除廣告�����。日志系統的需求提上日程。
這個日志系統必須支持分布式收集��、集中存儲��、實時����、可訂閱和簡單等特性。當時調研了一些開源系統�,比如Scribe總體不錯���,但是不支持訂閱�����。Kafka是Scala開發(fā)的���,但是團隊在Scala方面積累較少,Flume也是類似�����,而且比較重。所以開發(fā)團隊選擇了自己開發(fā)一個日志系統——Kids(Kids Is Data Stream)�。顧名思義,Kids是用來匯集各種數據流的��。
Kids參考了Scribe的思路����。Kdis在每臺服務器上可以配置成Agent或 Server。Agent直接接受來自應用的消息��,把消息匯集之后�����,可以打給下一個Agent或者直接打給中心Server�����。訂閱日志時���,可以從 Server上獲取��,也可以從中心節(jié)點的一些Agent上獲取��。

具體細節(jié)如下圖所示:
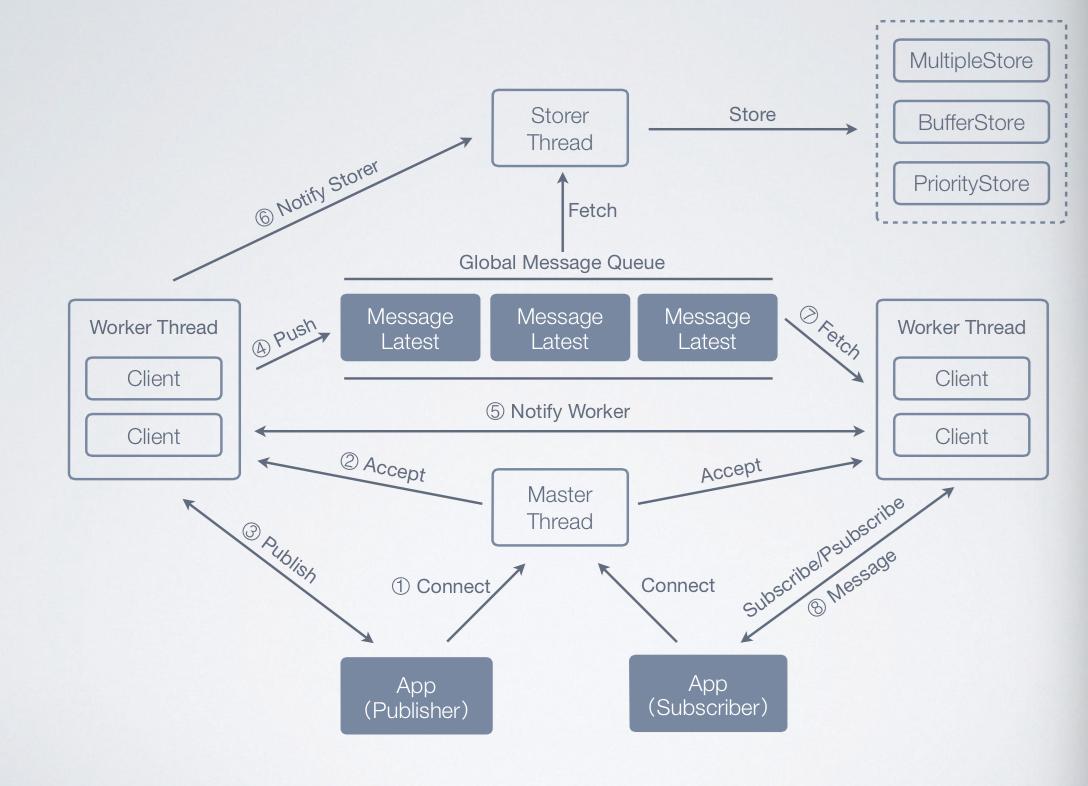
知乎還基于Kids做了一個Web小工具(Kids Explorer)���,支持實時看線上日志����,現在已經成為調試線上問題最主要的工具��。
Kids已經開源����,放到了Github上。
事件驅動的架構
知乎這個產品有一個特點�����,最早在添加一個答案后�,后續(xù)的操作其實只有更新通知�����、更新動 態(tài)����。但是隨著整個功能的增加,又多出了一些更新索引�����、更新計數、內容審查等操作��,后續(xù)操作五花八門����。如果按照傳統方式,維護邏輯會越來越龐大��,維護性也會 非常差���。這種場景很適合事件驅動方式�����,所以開發(fā)團隊對整個架構做了調整����,做了事件驅動的架構�。
這時首先需要的是一個消息隊列,它應該可以獲取到各種各樣的事件��,而且對一致性有很高的 要求���。針對這個需求��,知乎開發(fā)了一個叫Sink的小工具����。它拿到消息后,先做本地的保存���、持久化��,然后再把消息分發(fā)出去��。如果那臺機器掛掉了���,重啟時可以 完整恢復,確保消息不會丟失�����。然后它通過Miller開發(fā)框架��,把消息放到任務隊列����。Sink更像是串行消息訂閱服務,但任務需要并行化處理����, Beanstalkd就派上了用場,由其對任務進行全周期管理�。架構如下圖所示:
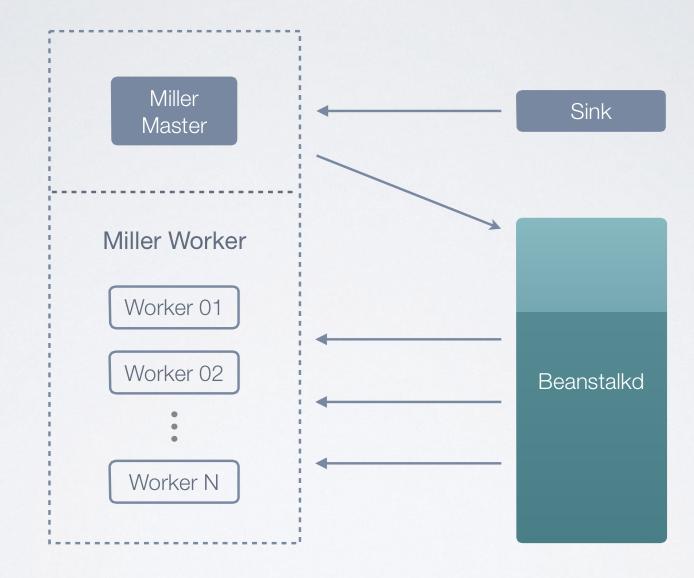
舉例而言,如果現在有用戶回答了問題���,首先系統會把問題寫到MySQL里面��,把消息塞到Sink�,然后把問題返回給用戶��。Sink通過Miller把任務發(fā)給 Beanstalkd�,Worker自己可以找到任務并處理。
最開始上線時����,每秒鐘有10個消息,然后有70個任務產生?,F在每秒鐘有100個事件,有1500個任務產生��,就是通過現在的事件驅動架構支撐的。
頁面渲染優(yōu)化
知乎在2013年時每天有上百萬的PV�����,頁面渲染其實是計算密集型的��,另外因為要獲取數據���,所以也有IO密集型的特點��。這時開發(fā)團隊就對頁面進行了組件化���,還升級了數據獲取機制。知乎按照整個頁面組件樹的結構�,自上而下分層地獲取數據,當上 層的數據已經獲取了�����,下層的數據就不需要再下去了��,有幾層基本上就有幾次數據獲取�。
結合這個思路,知乎自己做了一套模板渲染開發(fā)框架——ZhihuNode���。
經歷了一系列改進之后�,頁面的性能大幅度提升���。問題頁面從500ms 減少到150ms��,Feed頁面從1s減少到600ms�����。
面向服務的架構(SOA)
隨著知乎的功能越來越龐雜�,整個系統也越來越大���。知乎是怎么做的服務化呢����?
首先需要一個最基本的RPC框架���,RPC框架也經歷了好幾版演進�����。
第一版是Wish���,它是一個嚴格定義序列化的模型�����。傳輸層用到了STP�,這是自己寫的很 簡單的傳輸協議�,跑在TCP上。一開始用的還不錯��,因為一開始只寫了一兩個服務����。但是隨著服務增多,一些問題開始出現��,首先是 ProtocolBuffer會 生成一些描述代碼�����,很冗長����,放到整個庫里顯得很丑陋。另外嚴格的定義使其不便使用��。這時有位工程師開發(fā)了新的RPC框架——Snow。它使用簡單的 JSON做數據序列化�。但是松散的數據定義面對的問題是,比如說服務要去升級�,要改寫數據結構��,很難知道有哪幾個服務在使用��,也很難通知它們��,往往錯誤就 發(fā)生了���。于是又出了第三個RPC框架����,寫RPC框架的工程師���,希望結合前面兩個框架的特點��,首先保持Snow簡單����,其次需要相對嚴格的序列化協議���。這一版 本引入了 Apache Avro��。同時加入了特別的機制�����,在傳輸層和序列化協議這一層都做成了可插拔的方式�,既可以用JSON,也可以用Avro�����,傳輸層可以用STP��,也可以用 二進制協議�。
再就是搭了一個服務注冊發(fā)現,只需要簡單的定義服務的名字就可以找到服務在哪臺機器上���。同時�,知乎也有相應的調優(yōu)的工具�,基于Zipkin開發(fā)了自己的 Tracing系統。
按照調用關系�����,知乎的服務分成了3層:聚合層、內容層和基礎層����。按屬性又可以分成3類:數據服務、邏輯服務和通道服務���。數據服務主要是一些要做特殊數據類型的存儲��,比如圖片服務。邏輯服務更多的是CPU密集�、計算密集的操作,比如答案格式的定義���、解析等�����。通道服務的特點是沒有存儲���,更多是做一個轉發(fā),比如說Sink��。
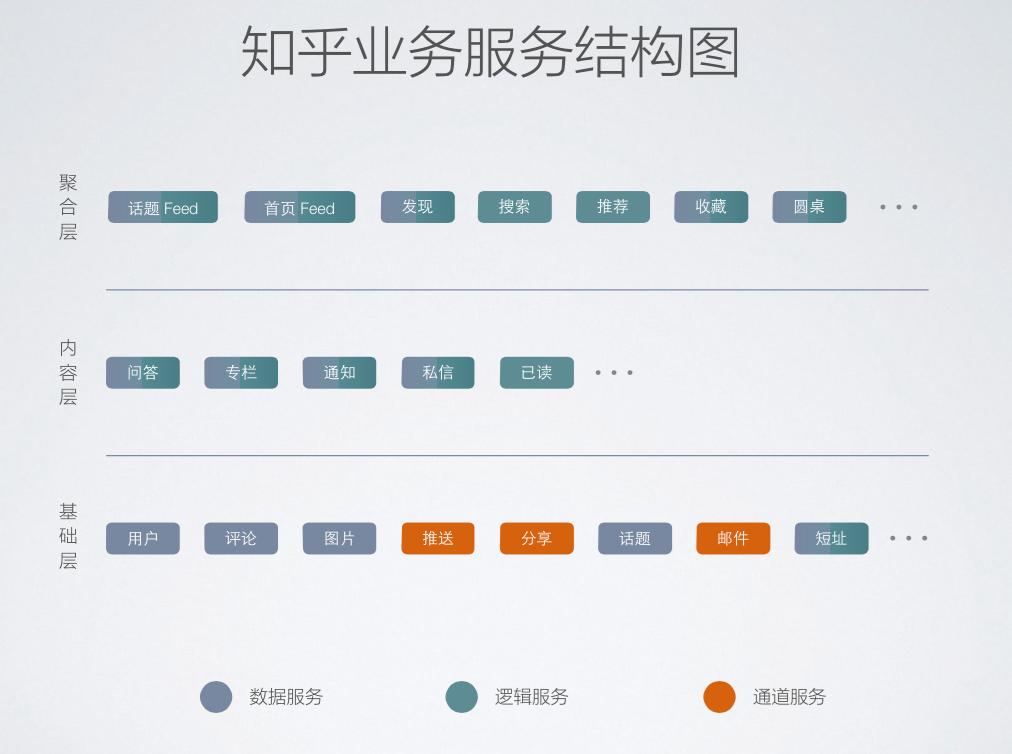
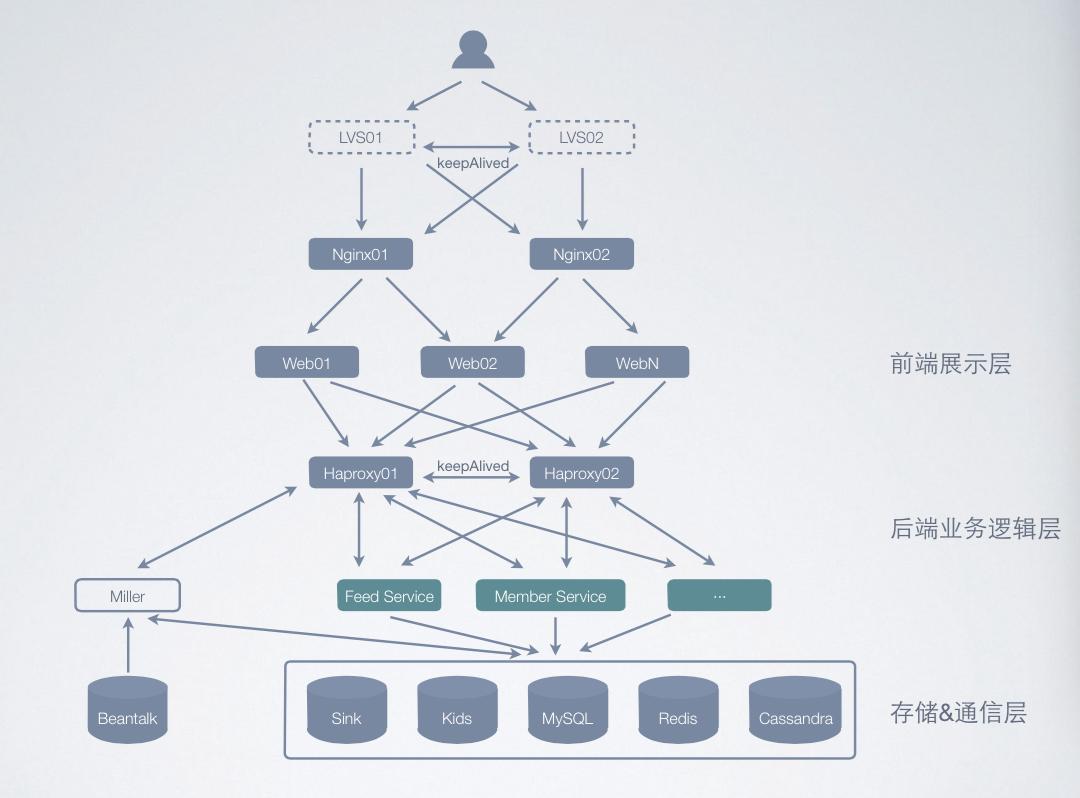
這是引入服務化之后整體的架構����。
而目前在產品方面��,知乎保留著以下幾個重點:
1.基礎模塊(1 問題-n 回答-n 評論模塊)
知乎基礎模塊中一個問題對應于 n 個回答�����,一個回答又對應于 n 個評論�����,因此我們可以把基礎模塊稱為 1 問題-n 回答-n 評論模塊����。假設知乎架構模型中僅存在基礎模塊�����,將會是一個怎樣的場景�?那就是信息流隨著時間的推移不斷生成新的內容并把舊信息快速替換沖刷掉,這種對基礎模塊無差別的線性陳列����,對用戶來說將是一個災難:
在簡單羅列的線性信息海洋中,用戶汲取其所需信息的成本太高;
信息流如同大河奔流����,那些有挖掘價值的信息點稍縱即逝,即信息價值被嚴重揮霍����;
用戶不能將有價值的信息點從信息大河里“舀”出來,信息可見而不可用����,無法產生長效作用。
知乎的產品設計者很好地意識到了這些潛在的“災難”����,并對每個問題點做出了針對性的產品設計方案����,下面木柄逐一展開分析。
2.話題模塊
話題模塊用來解決“在線性簡單羅列的信息海洋中�����,用戶汲取所需信息的成本太高”的問題�。知乎中,每一個基礎模塊(1 問題-n 回答-n 評論模塊)可以添加“話題”標識�,“話題”描述了基礎模塊的“類別”��,話題模塊與基礎模塊是多對多的映射關系(many2many)��。事實上���,為內容添加“標識”的做法在以內容為核心的網站的組織架構模型中屢見不鮮,很多網站將這種“標識”稱為標簽(比如 lofter)���。
但是知乎的話題比普通網站的標簽走的更遠:知乎的各個話題之間不像標簽那樣是孤立的��,它定義了一套將話題組織起來的數據結構��。請注意�����,話題本身就是對基礎模塊的一種組織形式��,而又存在一套數據結構描述了話題的組織形式�,那么我們可以將這種數據結構稱作“描述結構組織的結構組織”�����,知乎自己是這么介紹這個“描述結構組織的結構組織”:知乎的全部話題通過父子關系構成一個有根無循環(huán)的有向圖;根話題即為所有話題的最上層的父話題�����;請不要在問題上直接綁定根話題��。
3.發(fā)現模塊
發(fā)現模塊解決了信息流如同大河奔流���,那些有挖掘價值的信息點稍縱即逝���,即信息價值被嚴重揮霍的問題。發(fā)現模塊主要有兩部分內容組成:推薦與熱門��。熱門內容是由用戶群體行為所做出來的“內容精選”�����,而推薦內容是知乎運營人員對“群體行為”的補充完善��,最大程度地讓有價值的信息減緩流速�����,或者二次“逆流”��,目的就是讓有價值的信息得以“上浮”與“駐留”�。
此外值得一提的是,如果說發(fā)現模塊是構筑在知乎基礎模塊上的信息“駐留模塊”, 那么話題模塊也有一個針對其信息的“駐留模塊”——“話題精華模塊”�����。發(fā)現模塊是挖掘全局的有價值的信息�,而“話題精華模塊”挖掘的是該話題的有價值的信息,從而使有價值的信息在不同的組織維度上得到“駐留”����,而不被浩大的信息流沖的無影無蹤。
4.收藏模塊
收藏模塊解決了用戶不能將有價值的信息點從信息大河里“舀”出來����,信息可見而不可用,無法產生長效作用的問題��。收藏功能是很多內容為王的網站架構中重要的一環(huán)����,使用戶可以從浩淼的信息流中舀出其感興趣的那一瓢。知乎的收藏模塊支持創(chuàng)建收藏文件夾����,即用戶可以對收藏內容再組織���,存放到相應的收藏文件夾中。
此外知乎的收藏模塊還走的更遠��,用戶組織的收藏夾可以設置為“公有”狀態(tài)��,并分享給其他用戶��。也就是用戶的利己行為(收藏自己感興趣或者有幫助的內容)��,產生了利他的效果(其他用戶也能看到由別人的收藏夾并從中獲益)����。從內容組織角度上來說,知乎的收藏夾不但提供了將信息“舀”出保存的作用���,而且也起到將優(yōu)質信息“駐留”與“上浮”的作用�����。
5.知乎日報模塊
知乎日報模塊是一個比較特殊的模塊����,它并不是知乎的主體模塊�,你可以將其理解成知乎產品的衍生模塊,它事實上也從另外一個角度在解答信息價值被嚴重揮霍的問題���。知乎日報模塊與知乎主體模塊采用松耦合的架構模式��,它是對知乎這個龐大的優(yōu)質內容生產機器的二次開發(fā)���。知乎日報采取“日報”的方式,每天對知乎中產生的經典內容做一次組織成刊�。知乎日報簡單的布局、呈現方式����,更加符合人們在移動端的閱讀習慣,使那些覺得在移動端使用知乎不方便的用戶���,或者想在碎片時間里進行閱讀的用戶�,有一個更加貼心的知乎產品可以選擇����。
