前言
關系型數(shù)據(jù)庫比較容易成為系統(tǒng)瓶頸,單機存儲容量�����、連接數(shù)、處理能力都有限�,當數(shù)據(jù)量和并發(fā)量起來之后,就必須對數(shù)據(jù)庫進行切分了�����。
數(shù)據(jù)切分(sharding)的手段就是分庫分表��。分庫分表有兩方面�����,可能是光分庫不分表��,也可能是光分表不分庫����。
數(shù)據(jù)庫分布式的核心內(nèi)容無非就是數(shù)據(jù)切分,以及切分后對數(shù)據(jù)的定位���、整合�����。
為什么要分庫分表
分表
單表數(shù)據(jù)量太大時����,會嚴重影響sql執(zhí)行的性能。一般單表到達幾百萬的時候�,性能就會相對差一些了,這時就得分表了�。
分表就是把一個表的數(shù)據(jù)放到多個表中,然后查詢的時候就查一個表�����。比如按照項目id來分表:將固定數(shù)量的項目數(shù)據(jù)放在一個表中����,這樣就可以控制每個表的數(shù)據(jù)量在可控的范圍內(nèi)���。
分庫
根據(jù)經(jīng)驗來講�����,一個庫最多支持到并發(fā)2000時就需要擴容了���,而且一個健康的單庫并發(fā)值最好保持在1000左右。那么你可以將一個庫的數(shù)據(jù)拆分到多個庫中,訪問的時候就訪問一個庫好了�。
這就是所謂的分庫分表,為啥要分庫分表�����?
- 提高并發(fā)支撐能力
- 降低磁盤使用率
- 提高SQL執(zhí)行性能
如何分庫分表
直接看圖:
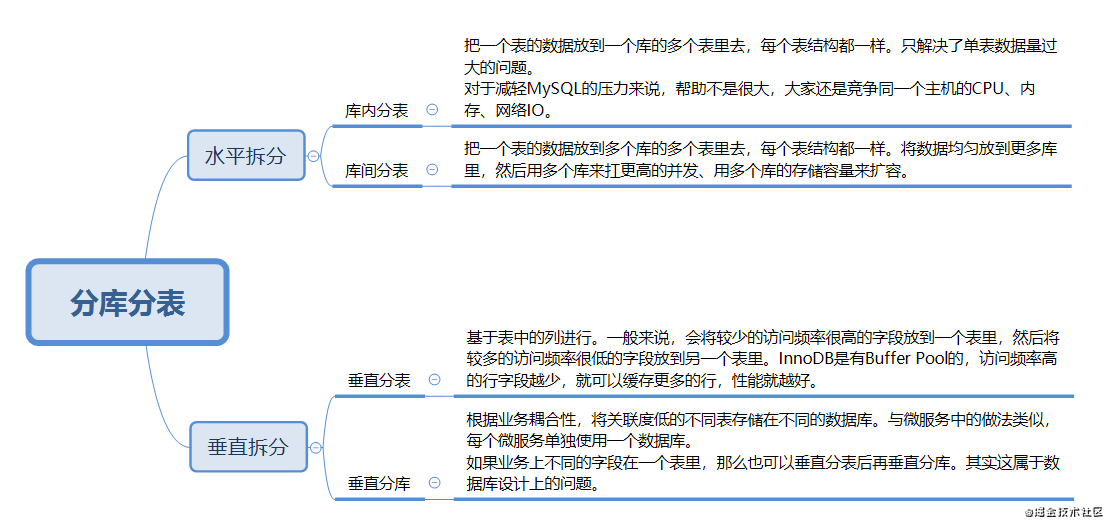
對于垂直拆分���,建議最好在系統(tǒng)設計之初做好表設計,避免垂直分表��。
水平拆分可以按照range來分��,或是按照某個字段hash�。按照range來分�����,好處在于擴容簡單��,準備好新的表或庫就可以了��。但是容易產(chǎn)生熱點問題�����,實際使用時要結合業(yè)務場景來看�����。按照hash來分��,好處在于可以平均分配每個庫或表的請求壓力�����,缺點是擴容麻煩�,之前的數(shù)據(jù)要rehash��,存在一個數(shù)據(jù)遷移的過程�。
分庫分表帶來的問題
分庫分表能有效地緩解單機和單庫帶來的網(wǎng)絡IO��、硬件資源����、連接數(shù)的壓力��。但也帶來了一些問題���。
- 事務一致性問題
通過分布式事務或者保證最終一致性來解決。
- 跨節(jié)點關聯(lián)查詢join問題
全局表����、字段冗余、數(shù)據(jù)組裝�����、ER分片
- 跨節(jié)點分頁���、排序�����、聚集函數(shù)問題
首先在不同分片節(jié)點進行查詢��,最后要對結果進行匯總或歸并
- 全局主鍵避重問題
各種分布式ID生成算法
- 數(shù)據(jù)遷移�、擴容問題
如果是range分片��,只需要添加節(jié)點就可以進行擴容了��。
如果是hash,一般做法是先讀出歷史數(shù)據(jù)���,然后按指定的分片規(guī)則再將數(shù)據(jù)寫入到各個分片節(jié)點中��。
數(shù)據(jù)遷移
數(shù)據(jù)遷移介紹兩種方案����。
一個最low的方案����,就是系統(tǒng)停機一段時間,用實現(xiàn)寫好的導數(shù)據(jù)的工具跑一遍把單獨單表的數(shù)據(jù)獨出來����,寫到分庫分表里面去。
第二個方案聽起來就比較靠譜了�����,雙寫遷移方案����。在線上系統(tǒng)里���,之前所有寫數(shù)據(jù)的地方��,增刪改操作�,除了對舊庫增刪改,再加上對新庫的增刪改���,這就是所謂的雙寫��。然后系統(tǒng)部署之后�,把方案一里的導數(shù)據(jù)工具跑起來����,讀老庫寫新庫。寫的時候要根據(jù)gmt_modified這類字段判斷這條數(shù)據(jù)最后修改的時間�,除非是讀出來新庫沒有,或是比新庫數(shù)據(jù)新才會寫�。簡單來說就是不允許用老數(shù)據(jù)覆蓋新數(shù)據(jù)。
寫完一輪之后��,有可能還是存在不一致�����,那么就程序自動新一輪校驗��,對比新老庫每個表的每條數(shù)據(jù),接著如果有不一樣的���,就針對那些不一樣的���,從老庫讀數(shù)據(jù)再次寫。反復循環(huán)直到數(shù)據(jù)完全一致��。
中間件
分庫分表的中間件比較常見的有:
- Cobar:阿里b2b團隊開發(fā)和開源的����,屬于proxy層方案,介于應用服務器和數(shù)據(jù)庫服務器之間���。應用程序通過JDBC驅動訪問Cobar集群���,Cobar根據(jù)SQL和分庫規(guī)則對SQL做分解,然后分發(fā)到MySQL集群不同的數(shù)據(jù)庫實例上執(zhí)行����。不支持讀寫分離、存儲過程�、跨庫join和分頁等操作。最近幾年都沒更新了,也沒啥人用了�����。
- TDDL:淘寶團隊開發(fā)的����,屬于client層方案���。支持基本的crud語法和讀寫分離�,但不支持join�����、多表查詢等語法��。目前只用也不多�,因為還依賴淘寶的diamond配置管理系統(tǒng)。
- Atlas:360開源的�����,屬于proxy層方案��。也是好幾年沒維護,現(xiàn)在用的公司基本也很少了���。
- Sharding-jdbc:當當開源的����,屬于client層方案�����,目前已更名為ShardingSphere����。SQL語法支持的也比較多,沒有太多限制��,支持分庫分表�、讀寫分離、分布式id生成���、柔性事務(最大努力送達型事務��、TCC事務)��。而且使用的公司比較多���,社區(qū)活躍���。
- Mycat:基于Cobar改造,屬于proxy層方案��。支持的功能非常完善�����。相比Sharding-jdbc來說����,年輕一些�。
綜上,現(xiàn)在可以考慮使用的就是Sharding-jdbc和Mycat����。
Sharding-jdbc這種client層方案的有點在于不用部署,運維成本低��,不需要代理層的二次轉發(fā)�����,性能高。缺點是有耦合性��。
Mycat這種proxy層方案的缺點在于需要部署�,自己運維一套中間件,運維成本高�,但是好處在于對項目是透明的。
MySQL分區(qū)(不建議使用)
這里介紹分區(qū)主要是防止和切分��、分庫分表等概念混淆��。
MySQL從5.1版本開始支持分區(qū)(partition)的功能��。分區(qū)指根據(jù)一定的規(guī)則��,數(shù)據(jù)庫把一個表分解成多個更小的�����、更容易管理的部分��。就訪問數(shù)據(jù)庫的應用而言�����,邏輯上只有一個表或一個索引����,但是實際上這個表可能由多個物理分區(qū)組成�����,即對應用是透明的���。
MySQL分區(qū)引入了分區(qū)鍵的概念,采取分治法�����,有利于管理非常大的表��。分區(qū)鍵用于根據(jù)某個區(qū)間值����、特定值列表或HASH函數(shù)執(zhí)行數(shù)據(jù)的聚集�����,讓數(shù)據(jù)根據(jù)規(guī)則分布在不同的分區(qū)中���。MySQL 5.7中可用的分區(qū)類型主要有以下6種:
- RANGE分區(qū):基于一個給定連續(xù)區(qū)間范圍�,把數(shù)據(jù)分配到不同的分區(qū)。
- LIST分區(qū):類似RANGE分區(qū)��,區(qū)別在LIST分區(qū)是基于枚舉出的值列表分區(qū)�,RANGE是基于給定的連續(xù)區(qū)間范圍分區(qū)。
- COLUMNS分區(qū):類似于RANGE和LIST���,區(qū)別在于分區(qū)鍵既可以是多列����,又可以是非整數(shù)����。
- HASH分區(qū):基于給定的分區(qū)個數(shù),把數(shù)據(jù)取模分配到不同的分區(qū)���。
- KEY分區(qū):類似于HASH分區(qū)����,但使用MySQL提供的哈希函數(shù)���。
- 子分區(qū):也叫做復合分區(qū)或者組合分區(qū)����,即在主分區(qū)下再做一層分區(qū),將數(shù)據(jù)再次分割��。
這里舉一LIST分區(qū)的例子:
CREATE TABLE orders_list (
id INT AUTO_INCREMENT,
customer_surname VARCHAR(30),
store_id INT,
salesperson_id INT,
order_date DATE,
note VARCHAR(500),
INDEX idx (id)
) ENGINE = INNODB
PARTITION BY LIST(store_id) (
PARTITION p1
VALUES IN (1, 3, 4, 17)
INDEX DIRECTORY = '/var/orders/district1'
DATA DIRECTORY = '/var/orders/district1',
PARTITION p2
VALUES IN (2, 12, 14)
INDEX DIRECTORY = '/var/orders/district2'
DATA DIRECTORY = '/var/orders/district2',
PARTITION p3
VALUES IN (6, 8, 20)
INDEX DIRECTORY = '/var/orders/district3'
DATA DIRECTORY = '/var/orders/district3',
PARTITION p4
VALUES IN (5, 7, 9, 11, 16)
INDEX DIRECTORY = '/var/orders/district4'
DATA DIRECTORY = '/var/orders/district4',
PARTITION p5
VALUES IN (10, 13, 15, 18)
INDEX DIRECTORY = '/var/orders/district5'
DATA DIRECTORY = '/var/orders/district5'
);
分區(qū)的優(yōu)點:
- 擴大存儲容量�����。
- 優(yōu)化查詢��。在WHERE子句中包含分區(qū)條件時可以只掃描必要的分區(qū)來提高查詢效率����;同事在涉及SUM()和COUNT()這類聚合函數(shù)的查詢時,可以在每個分區(qū)上并行處理�����。
- 對于已經(jīng)過期或不需要保存的數(shù)據(jù)分區(qū)����,可以通過刪除分區(qū)來快速刪除數(shù)據(jù)��。
- 跨多磁盤來分散查詢數(shù)據(jù)����,獲得更大的查詢吞吐量�����。
總結
到此這篇關于MySQL分庫分表與分區(qū)的文章就介紹到這了,更多相關MySQL分庫分表分區(qū)內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家�����!
您可能感興趣的文章:- 淺談訂單重構之 MySQL 分庫分表實戰(zhàn)篇
- mysql死鎖和分庫分表問題詳解
- MySQL 分表分庫怎么進行數(shù)據(jù)切分
- MySql分表�、分庫���、分片和分區(qū)知識深入詳解
- MySql分表��、分庫�、分片和分區(qū)知識點介紹
- MySQL分庫分表總結講解
- mysql分表分庫的應用場景和設計方式
- mysql數(shù)據(jù)庫分表分庫的策略
- MyBatis實現(xiàn)Mysql數(shù)據(jù)庫分庫分表操作和總結(推薦)
- MYSQL數(shù)據(jù)庫數(shù)據(jù)拆分之分庫分表總結
- Mysql數(shù)據(jù)庫分庫和分表方式(常用)
- MYSQL性能優(yōu)化分享(分庫分表)
- MySQL分庫分表詳情
