目錄
- 前言
- 加載模型
- 構建詞網(wǎng)
- 維特比算法
- 實戰(zhàn)
前言
在機器學習中�����,我們有了訓練集的話���,就開始預測���。預測是指利用模型對句子進行推斷的過程。在中文分詞任務中也就是利用模型推斷分詞序列�,同時也叫解碼。
在HanLP庫中����,二元語法的解碼由ViterbiSegment分詞器提供����。本篇將詳細介紹ViterbiSegment的使用方式
加載模型
在前篇博文中,我們已經(jīng)得到了訓練的一元,二元語法模型�����。后續(xù)的處理肯定會基于這幾個文件來處理���。所以���,我們首先要做的就是加載這些模型到程序中:
if __name__ == "__main__":
MODEL_PATH = "123"
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
CoreDictionary = SafeJClass("com.hankcs.hanlp.dictionary.CoreDictionary")
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
print(CoreDictionary.getTermFrequency("秦機"))
print(CoreBiGramTableDictionary.getBiFrequency("秦機","的"))
運行之后,效果如下:

這里我們使用CoreDictionary.getTermFrequency()方法獲取”秦機“的頻次��。使用CoreBiGramTableDictionary.getBiFrequency()方法獲取“秦機 的”的二元語法頻次�����。
構建詞網(wǎng)
在前文中我們介紹了符號“末##末“��,代表句子結尾���,”始##始“代表句子開頭��。而詞網(wǎng)指的是句子中所有一元語法構成的網(wǎng)狀結構��。比如MSR詞典中的“秦機和科技”這個句子��,是給定的一元詞典�����。我們將句子中所有單詞找出來�。得到如下詞網(wǎng):
[始##始]
[秦機]
[]
[和,和科]
[科技]
[技]
[末##末]
對應的此圖如下所示:
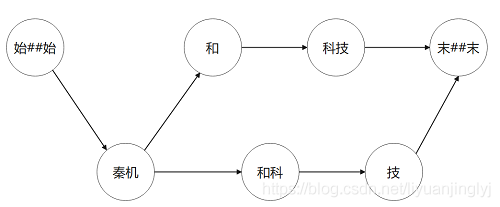
當然�,這里博主只是舉例說明詞網(wǎng)的概念,“和科”并不是一個單詞����。
下面,我們來通過方法構建詞網(wǎng)��。具體代碼如下:
def build_wordnet(sent, trie):
JString = JClass('java.lang.String')
Vertex = JClass('com.hankcs.hanlp.seg.common.Vertex')
WordNet = JClass('com.hankcs.hanlp.seg.common.WordNet')
searcher = trie.getSearcher(JString(sent), 0)
wordnet = WordNet(sent)
while searcher.next():
wordnet.add(searcher.begin + 1,
Vertex(sent[searcher.begin:searcher.begin + searcher.length], searcher.value, searcher.index))
# 原子分詞����,保證圖連通
vertexes = wordnet.getVertexes()
i = 0
while i len(vertexes):
if len(vertexes[i]) == 0: # 空白行
j = i + 1
for j in range(i + 1, len(vertexes) - 1): # 尋找第一個非空行 j
if len(vertexes[j]):
break
wordnet.add(i, Vertex.newPunctuationInstance(sent[i - 1: j - 1])) # 填充[i, j)之間的空白行
i = j
else:
i += len(vertexes[i][-1].realWord)
return wordnet
if __name__ == "__main__":
MODEL_PATH = "123"
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
CoreDictionary = SafeJClass("com.hankcs.hanlp.dictionary.CoreDictionary")
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
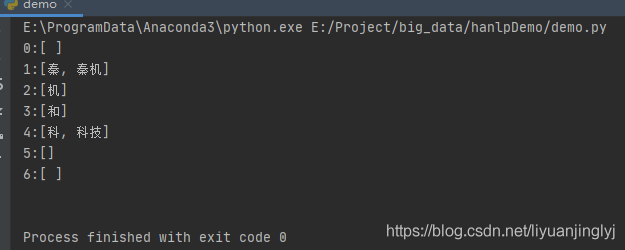
print(build_wordnet("秦機和科技", CoreDictionary.trie))
運行之后,我們會得到與上圖歸納差不多的內容:
維特比算法
如果現(xiàn)在我們賦予上述詞圖每條邊以二元語法的概率作為距離����,那么如何求解詞圖上的最短路徑就是一個關鍵問題。
假設文本長度為n���,則一共有2(n-1次方)種切分方式�,因為每2個字符間都有2種選擇:切或者不切���,時間復雜度就為O(2(n-1次方))��。顯然不切實際�����,這里我們考慮使用維特比算法��。
維特比算法原理:它分為前向和后向兩個步驟����。
- 前向:由起點出發(fā)從前往后遍歷節(jié)點�,更新從起點到該節(jié)點的最下花費以及前驅指針
- 后向:由終點出發(fā)從后往前回溯前驅指針,取得最短路徑
維特比算法用python代碼的實現(xiàn)如下:
def viterbi(wordnet):
nodes = wordnet.getVertexes()
# 前向遍歷
for i in range(0, len(nodes) - 1):
for node in nodes[i]:
for to in nodes[i + len(node.realWord)]:
# 根據(jù)距離公式計算節(jié)點距離�����,并維護最短路徑上的前驅指針from
to.updateFrom(node)
# 后向回溯
# 最短路徑
path = []
# 從終點回溯
f = nodes[len(nodes) - 1].getFirst()
while f:
path.insert(0, f)
# 按前驅指針from回溯
f = f.getFrom()
return [v.realWord for v in path]
實戰(zhàn)
現(xiàn)在我們來做個測試���,我們在msr_test_gold.utf8上訓練模型��,為秦機和科技常見詞圖���,最后運行維特比算法����。詳細代碼如下所示:
if __name__ == "__main__":
MODEL_PATH = "123"
corpus_path = r"E:\ProgramData\Anaconda3\Lib\site-packages\pyhanlp\static\data\test\icwb2-data\gold\msr_test_gold.utf8"
train_model(corpus_path, MODEL_PATH)
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
CoreDictionary = SafeJClass("com.hankcs.hanlp.dictionary.CoreDictionary")
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
ViterbiSegment = JClass('com.hankcs.hanlp.seg.Viterbi.ViterbiSegment')
MODEL_PATH = "123"
HanLP.Config.CoreDictionaryPath = MODEL_PATH + ".txt"
HanLP.Config.BiGramDictionaryPath = MODEL_PATH + ".ngram.txt"
sent = "秦機和科技"
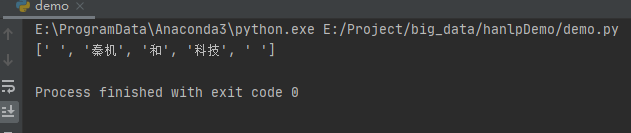
wordnet = build_wordnet(sent, CoreDictionary.trie)
print(viterbi(wordnet))
有的人可能有疑問���,因為二元模型里����,本身就存在秦機 和
科技這個樣本���。這么做不是多此一舉嗎?那好���,我們替換sent的文本內容為“北京和廣州”�,這個樣本可不在模型中���。運行之后�,效果如下:

我們發(fā)現(xiàn)依然能正確的分詞為[北京 和 廣州]�,這就是二元語法模型的泛化能力��。至此我們走通了語料標注,訓練模型�����,預測分詞結果的完整步驟。
到此這篇關于Python預測分詞的實現(xiàn)的文章就介紹到這了,更多相關Python預測分詞內容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持腳本之家����!
您可能感興趣的文章:- python jieba分詞并統(tǒng)計詞頻后輸出結果到Excel和txt文檔方法
- Python基于jieba庫進行簡單分詞及詞云功能實現(xiàn)方法
- python中文分詞庫jieba使用方法詳解
- python中文分詞,使用結巴分詞對python進行分詞(實例講解)
- python實現(xiàn)中文分詞FMM算法實例
- Python中文分詞庫jieba,pkusegwg性能準確度比較
- python實現(xiàn)機械分詞之逆向最大匹配算法代碼示例
