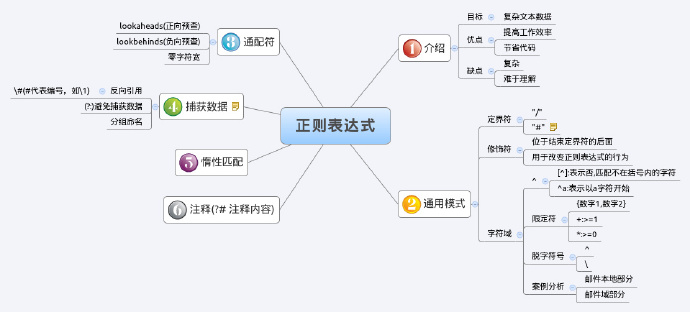
思維導圖
介紹
正則表達式�,大家在開發(fā)中應該是經(jīng)常用到,現(xiàn)在很多開發(fā)語言都有正則表達式的應用����,比如JavaScript、Java���、.Net����、PHP 等,我今天就把我對正則表達式的理解跟大家嘮嘮��,不當之處���,請多多指教�����!
需要知道的術(shù)語——下面的術(shù)語你知道多少?
Δ 定界符
Δ 字符域
Δ 修飾符
Δ 限定符
Δ 脫字符
Δ 通配符(正向預查����,反向預查)
Δ 反向引用
Δ 惰性匹配
Δ 注釋
Δ 零字符寬
定位
我們什么時候使用正則表達式呢�?不是所有的字符操作都用正則就好了,php在某些方面用正則反而影響效率��。當我們遇到復雜文本數(shù)據(jù)的解析時候���,用正則是比較好的選擇���。
優(yōu)點
正則表達式在處理復雜字符操作的時候�,可以提高工作效率�����,也在一定程度節(jié)省你的代碼量�。
缺點
我們在使用正則表達式的時候,復雜的正則表達式會加大代碼的復雜度�,讓人很難理解。所以我們有的時候需要在正則表達式內(nèi)部添加注釋��。
通用模式
¤ 定界符��,通常使用 “/”做為定界符開始和結(jié)束,也可以使用”#”���。
什么時候使用”#”呢?一般是在你的字符串中有很多”/”字符的時候,因為正則的時候這種字符需要轉(zhuǎn)義����,比如uri。
使用”/”定界符的代碼如下.
$regex = '/^http:\/\/([\w.]+)\/([\w]+)\/([\w]+)\.html$/i';
$str = 'http://www.youku.com/show_page/id_ABCDEFG.html';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
preg_match中的$matches[0]將包含與整個模式匹配的字符串�����。
使用”#”定界符的代碼如下.這個時候?qū)Α?”就不轉(zhuǎn)義!
$regex = '#^http://([\w.]+)/([\w]+)/([\w]+)\.html$#i';
$str = 'http://www.youku.com/show_page/id_ABCDEFG.html';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
¤ 修飾符:用于改變正則表達式的行為�。
我們看到的(‘/^http:\/\/([\w.]+)\/([\w]+)\/([\w]+)\.html/i‘)中的最后一個”i”就是修飾符,表示忽略大小寫�����,還有一個我們經(jīng)常用到的是”x”表示忽略空格����。
貢獻代碼:
$regex = '/HELLO/';
$str = 'hello word';
$matches = array();
if(preg_match($regex, $str, $matches)){
echo 'No i:Valid Successful!',"\n";
}
if(preg_match($regex.'i', $str, $matches)){
echo 'YES i:Valid Successful!',"\n";
}
¤ 字符域:[\w]用方括號擴起來的部分就是字符域�����。
¤ 限定符:如[\w]{3,5}或者[\w]*或者[\w]+這些[\w]后面的符號都表示限定符?����,F(xiàn)介紹具體意義����。
{3,5}表示3到5個字符。{3,}超過3個字符�����,{,5}最多5個�,{3}三個字符。
* 表示0到多個
+ 表示1到多個��。
¤ 脫字符號
^:
> 放在字符域(如:[^\w])中表示否定(不包括的意思)——“反向選擇”
> 放在表達式之前,表示以當前這個字符開始�����。(/^n/i,表示以n開頭)����。
注意,我們經(jīng)常管”\”叫”跳脫字符”����。用于轉(zhuǎn)義一些特殊符號,如”.”,”/”
通配符(lookarounds):斷言某些字符串中某些字符的存在與否��!
lookarounds分兩種:lookaheads(正向預查 ?=)和lookbehinds(反向預查?=)���。
> 格式:
正向預查:(?=) 相對應的 (?!)表示否定意思
反向預查:(?=) 相對應的 (?!)表示否定意思
前后緊跟字符
$regex = '/(?=c)d(?=e)/';
/* d 前面緊跟c, d 后面緊跟e*/
$str = 'abcdefgk';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
否定意義:
$regex = '/(?!c)d(?!e)/';
/* d 前面不緊跟c, d 后面不緊跟e*/
$str = 'abcdefgk';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
>字符寬度:零
驗證零字符代碼
$regex = '/HE(?=L)LO/i';
$str = 'HELLO';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
打印不出結(jié)果!
$regex = '/HE(?=L)LLO/i';
$str = 'HELLO';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
能打印出結(jié)果!
說明:(?=L)意思是HE后面緊跟一個L字符��。但是(?=L)本身不占字符�,要與(L)區(qū)分,(L)本身占一個字符����。
捕獲數(shù)據(jù)
沒有指明類型而進行的分組,將會被獲取,供以后使用�。
> 指明類型指的是通配符����。所以只有圓括號起始位置沒有問號的才能被捕捉。
> 在同一個表達式內(nèi)的引用叫做反向引用�����。
> 調(diào)用格式: \編號(如\1)��。
$regex = '/^(Chuanshanjia)[\w\s!]+\1$/';
$str = 'Chuanshanjia thank Chuanshanjia';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
> 避免捕獲數(shù)據(jù)
格式:(?:pattern)
優(yōu)點:將使有效反向引用數(shù)量保持在最小�����,代碼更加��、清楚����。
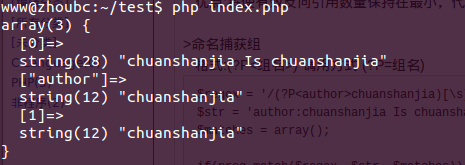
>命名捕獲組
格式:(?P組名>) 調(diào)用方式 (?P=組名)
$regex = '/(?Pauthor>chuanshanjia)[\s]Is[\s](?P=author)/i';
$str = 'author:chuanshanjia Is chuanshanjia';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
運行結(jié)果
惰性匹配(記住:會進行兩部操作,請看下面的原理部分)
格式:限定符?
原理:”?”:如果前面有限定符�����,會使用最小的數(shù)據(jù)。如“*”會取0個�����,而“+”會取1個��,如過是{3,5}會取3個���。
先看下面的兩個代碼:
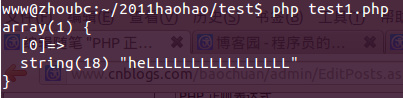
代碼1.
?php
$regex = '/heL*/i';
$str = 'heLLLLLLLLLLLLLLLL';
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
結(jié)果1.
代碼2
?php
$regex = '/heL*?/i';
$str = 'heLLLLLLLLLLLLLLLL';
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
結(jié)果2
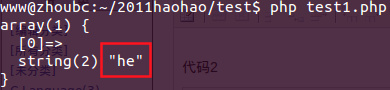
代碼3,使用“+”
?php
$regex = '/heL+?/i';
$str = 'heLLLLLLLLLLLLLLLL';
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
結(jié)果3
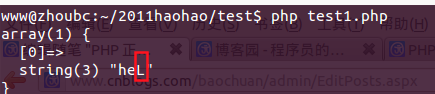
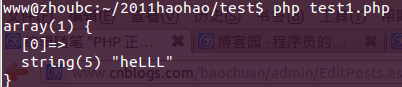
代碼4,使用{3,5}
?php
$regex = '/heL{3,10}?/i';
$str = 'heLLLLLLLLLLLLLLLL';
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
結(jié)果4
正則表達式的注釋
格式:(?# 注釋內(nèi)容)
用途:主要用于復雜的注釋
貢獻代碼:是一個用于連接MYSQL數(shù)據(jù)庫的正則表達式
$regex = '/
^host=(?!\.)([\d.]+)(?!\.) (?#主機地址)
\|
([\w!@#$%^*()_+\-]+) (?#用戶名)
\|
([\w!@#$%^*()_+\-]+) (?#密碼)
(?!\|)$/ix';
$str = 'host=192.168.10.221|root|123456';
$matches = array();
if(preg_match($regex, $str, $matches)){
var_dump($matches);
}
echo "\n";
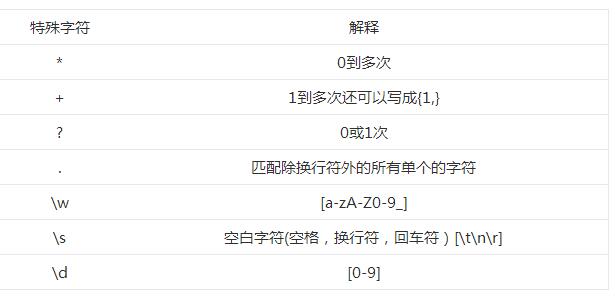
特殊字符
想要學好php正則表達式����,僅僅學習這一篇文章是遠遠夠的�����,希望大家堅持學習����,閱讀php正則表達式相關(guān)文章。
您可能感興趣的文章:- 最常用的PHP正則表達式收集整理
- PHP 正則表達式常用函數(shù)使用小結(jié)
- 非常重要的php正則表達式詳解
- php正則表達式使用的詳細介紹
- php中字符串和正則表達式詳解
- php使用正則表達式提取字符串中尖括號����、小括號�����、中括號、大括號中的字符串
- php過濾HTML標簽����、屬性等正則表達式匯總
- php的正則表達式完全手冊
- PHP中的正則表達式實例詳解
- 日常收集整理php正則表達式(超常用)
- PHP正則表達式筆記與實例詳解
