正則表達式零寬斷言:
零寬斷言是正則表達式中的難點,所以本章節(jié)重點從匹配原理方面進行一下分析。零寬斷言還有其他的名稱,例如"環(huán)視"或者"預搜索"等等��,不過這些都不是我們關(guān)注的重點��。
一.基本概念:
零寬斷言正如它的名字一樣��,是一種零寬度的匹配���,它匹配到的內(nèi)容不會保存到匹配結(jié)果中去���,最終匹配結(jié)果只是一個位置而已�。
作用是給指定位置添加一個限定條件��,用來規(guī)定此位置之前或者之后的字符必須滿足限定條件才能使正則中的字表達式匹配成功��。
注意:這里所說的子表達式并非只有用小括號括起來的表達式���,而是正則表達式中的任意匹配單元���。
javascript只支持零寬先行斷言,而零寬先行斷言又可以分為正向零寬先行斷言�����,和負向零寬先行斷言。
代碼實例如下:
實例代碼一:
var str="abZW863";
var reg=/ab(?=[A-Z])/;
console.log(str.match(reg));
在以上代碼中����,正則表達式的語義是:匹配后面跟隨任意一個大寫字母的字符串"ab"。最終匹配結(jié)果是"ab"�,因為零寬斷言"(?=[A-Z])"并不匹配任何字符,只是用來規(guī)定當前位置的后面必須是一個大寫字母�。
實例代碼二:
var str="abZW863";
var reg=/ab(?![A-Z])/;
console.log(str.match(reg));
以上代碼中,正則表達式的語義是:匹配后面不跟隨任意一個大寫字母的字符串"ab"�����。正則表達式?jīng)]能匹配任何字符��,因為在字符串中����,ab的后面跟隨有大寫字母。
二.匹配原理:
上面代碼只是用概念的方式介紹了零寬斷言是如何匹配的����。
下面就以匹配原理的方式分別介紹一下正向零寬斷言和負向零寬斷言是如何匹配的。
1.正向零寬斷言:
代碼實例如下:
var str="div>antzone";
var reg=/^(?=)[^>]+>\w+/;
console.log(str.match(reg));

匹配過程如下:
首先由正則表達式中的"^"獲取控制權(quán),首先由位置0開始進行匹配�����,它匹配開始位置0���,匹配成功�����,然后控制權(quán)轉(zhuǎn)交給"(?=)"��,,由于"^"是零寬的�,所以"(?=)"也是從位置0處開始匹配����,它要求所在的位置右側(cè)必須是字符""�����,位置0的右側(cè)恰好是字符""�����,匹配成功,然后控制權(quán)轉(zhuǎn)交個"",由于"(?=)"也是零寬的��,所以它也是從位置0處開始匹配����,于是匹配成功,后面的匹配過程就不介紹了���。
2.負向零寬斷言:
代碼實例如下:
var str="abZW863ab88";
var reg=/ab(?![A-Z])/g;
console.log(str.match(reg));
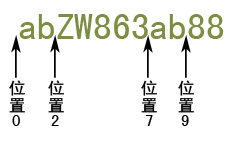
匹配過程如下:
首先由正則表達式的字符"a"獲取控制權(quán)����,從位置0處開始匹配�,匹配字符"a"成功,然后控制權(quán)轉(zhuǎn)交給"b"��,從位置1處開始匹配����,配字符"b"成功,然后控制權(quán)轉(zhuǎn)交給"(?![A-Z])"�,它從位置2處開始匹配,它要求所在位置的右邊不能夠是任意一個大寫字母�,而位置的右邊是大寫字母"Z",匹配失敗,然后控制權(quán)又重新交給字符"a"�,并從位置1處開始嘗試,匹配失敗,然后控制權(quán)再次交給字符"a"����,從位置2處開始嘗試匹配,依然失敗�����,如此往復嘗試�����,直到從位置7處開始嘗試匹配成功��,然后將控制權(quán)轉(zhuǎn)交給"b",然后從位置8處開始嘗試匹配����,匹配成功,然后再將控制權(quán)轉(zhuǎn)交給"(?![A-Z])"�����,它從位置9處開始嘗試匹配��,它規(guī)定它所在的位置右邊不能夠是大寫字母���,匹配成功��,但是它并不會真正匹配字符����,所以最終匹配結(jié)果是"ab"��。
以下是補充
零寬斷言是正則表達式中的一種方法��,正則表達式在計算機科學中�����,是指一個用來描述或者匹配一系列符合某個句法規(guī)則的字符串的單個字符串�����。
定義解釋
零寬斷言是正則表達式中的一種方法
正則表達式在計算機科學中��,是指一個用來描述或者匹配一系列符合某個句法規(guī)則的字符串的單個字符串��。在很多文本編輯器或其他工具里�,正則表達式通常被用來檢索和/或替換那些符合某個模式的文本內(nèi)容。許多程序設(shè)計語言都支持利用正則表達式進行字符串操作�����。例如,在Perl中就內(nèi)建了一個功能強大的正則表達式引擎���。正則表達式這個概念最初是由Unix中的工具軟件(例如sed和grep)普及開的����。正則表達式通??s寫成“regex”,單數(shù)有regexp���、regex����,復數(shù)有regexps��、regexes�����、regexen�����。
零寬斷言
用于查找在某些內(nèi)容(但并不包括這些內(nèi)容)之前或之后的東西��,也就是說它們像\b,^,$那樣用于指定一個位置����,這個位置應(yīng)該滿足一定的條件(即斷言),因此它們也被稱為零寬斷言���。最好還是拿例子來說明吧: 斷言用來聲明一個應(yīng)該為真的事實�。正則表達式中只有當斷言為真時才會繼續(xù)進行匹配���。
(?=exp)也叫零寬度正預測先行斷言���,它斷言自身出現(xiàn)的位置的后面能匹配表達式exp。比如\b(?=re)\w+\b���,匹配以re開頭的單詞的后面部分(除了re以外的部分)�,如查找reading a book.時�,它會匹配ading。
var reg = new Regex(@"\w+(?=ing)");
var str = "muing";
Console.WriteLine(reg.Match(str).Value);//返回mu
(?=exp)也叫零寬度正回顧后發(fā)斷言�,它斷言自身出現(xiàn)的位置的前面能匹配表達式exp。比如\b\w+(?=ing\b)會匹配以ing結(jié)尾的單詞的前半部分(除了ing以外的部分)��,例如在查找I am reading.時,它匹配read�����。
假如你想要給一個很長的數(shù)字中每三位間加一個逗號(當然是從右邊加起了)����,你可以這樣查找需要在前面和里面添加逗號的部分:((?=\d)\d{3})+\b,用它對1234567890進行查找時結(jié)果是234567890�。
下面這個例子同時使用了這兩種斷言:(?=\s)\d+(?=\s)匹配以空白符間隔的數(shù)字(再次強調(diào),不包括這些空白符)����。
負向零寬斷言
前面我們提到過怎么查找不是某個字符或不在某個字符類里的字符的方法(反義)。但是如果我們只是想要確保某個字符沒有出現(xiàn)�����,但并不想去匹配它時怎么辦��?例如�,如果我們想查找這樣的單詞--它里面出現(xiàn)了字母q,但是q后面跟的不是字母u,我們可以嘗試這樣:
\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的單詞。但是如果多做測試(或者你思維足夠敏銳��,直接就觀察出來了)�����,你會發(fā)現(xiàn)���,如果q出現(xiàn)在單詞的結(jié)尾的話����,像Iraq,Benq��,這個表達式就會出錯����。這是因為[^u]總要匹配一個字符,所以如果q是單詞的最后一個字符的話�����,后面的[^u]將會匹配q后面的單詞分隔符(可能是空格��,或者是句號或其它的什么)�,后面的\w*\b將會匹配下一個單詞,于是\b\w*q[^u]\w*\b就能匹配整個Iraq fighting���。負向零寬斷言能解決這樣的問題�,因為它只匹配一個位置,并不消費任何字符?���,F(xiàn)在,我們可以這樣來解決這個問題:\b\w*q(?!u)\w*\b��。
零寬度負預測先行斷言(?!exp)��,斷言此位置的后面不能匹配表達式exp����。例如:\d{3}(?!\d)匹配三位數(shù)字,而且這三位數(shù)字的后面不能是數(shù)字����;\b((?!abc)\w)+\b匹配不包含連續(xù)字符串a(chǎn)bc的單詞。
同理�����,我們可以用(?!exp),零寬度負回顧后發(fā)斷言來斷言此位置的前面不能匹配表達式exp:(?![a-z])\d{7}匹配前面不是小寫字母的七位數(shù)字�����。
一個更復雜的例子:(?=(\w+)>).*(?=\/\1>)匹配不包含屬性的簡單HTML標簽內(nèi)里的內(nèi)容。(?=(\w+)>)指定了這樣的前綴:被尖括號括起來的單詞(比如可能是b>)���,然后是.*(任意的字符串),最后是一個后綴(?=\/\1>)���。注意后綴里的\/,它用到了前面提過的字符轉(zhuǎn)義�����;\1則是一個反向引用�����,引用的正是捕獲的第一組�����,前面的(\w+)匹配的內(nèi)容����,這樣如果前綴實際上是b>的話����,后綴就是/b>了。整個表達式匹配的是b>和/b>之間的內(nèi)容(再次提醒,不包括前綴和后綴本身)���。
上面的看了有點傷腦筋啊����。下面來點補充一
斷言用來聲明一個應(yīng)該為真的事實�。正則表達式中只有當斷言為真時才會繼續(xù)進行匹配。
接下來的四個用于查找在某些內(nèi)容(但并不包括這些內(nèi)容)之前或之后的東西��,也就是說它們像\b,^,$那樣用于指定一個位置��,這個位置應(yīng)該滿足一定的條件(即斷言)�����,因此它們也被稱為零寬斷言�����。最好還是拿例子來說明吧:
(?=exp)也叫零寬度正預測先行斷言�����,它斷言自身出現(xiàn)的位置的后面能匹配表達式exp�����。比如\b\w+(?=ing\b),匹配以ing結(jié)尾的單詞的前面部分(除了ing以外的部分)�����,如查找I'm singing while you're dancing.時��,它會匹配sing和danc���。
(?=exp)也叫零寬度正回顧后發(fā)斷言,它斷言自身出現(xiàn)的位置的前面能匹配表達式exp�。比如(?=\bre)\w+\b會匹配以re開頭的單詞的后半部分(除了re以外的部分),例如在查找reading a book時��,它匹配ading���。
假如你想要給一個很長的數(shù)字中每三位間加一個逗號(當然是從右邊加起了)���,你可以這樣查找需要在前面和里面添加逗號的部分:((?=\d)\d{3})*\b,用它對1234567890進行查找時結(jié)果是234567890�����。
下面這個例子同時使用了這兩種斷言:(?=\s)\d+(?=\s)匹配以空白符間隔的數(shù)字(再次強調(diào),不包括這些空白符)���。
補充二:
最近為了對html文件進行源碼處理���,需要進行正則查找并替換。于是借著這個機會把正則系統(tǒng)地學一下�,雖然以前也用過正則,但每次都是臨時學一下混過關(guān)的�����。在學習的過程中還是遇到不少問題的���,特別是零寬斷言(這里還要吐槽下����,網(wǎng)上到處都是都復制粘貼的內(nèi)容��,遇到個問題查看了不少重復的東西����,汗!?���。�����。?�,所以在這里把自己的理解寫下來���,方便以后查閱!
零寬度正預測先行斷言是什么呢����,看msdn上的官方解釋定義
(?= 子表達式)
(零寬度正預測先行斷言。)僅當子表達式在此位置的右側(cè)匹配時才繼續(xù)匹配�。例如�����,\w+(?=\d) 與后跟數(shù)字的單詞匹配�,而不與該數(shù)字匹配。
經(jīng)典的例子:某單詞以ing結(jié)尾��,要獲取ing前面的內(nèi)容
var reg = new Regex(@"\w+(?=ing)");
var str = "muing";
Console.WriteLine(reg.Match(str).Value);//返回mu
以上是網(wǎng)上到處可見的例子�,到這里或許你明白了����,原來就是返回了exp表達式前面的內(nèi)容�。
再看下面的的代碼
var reg = new Regex(@"a(?=b)c");
var str = "abc";
Console.WriteLine(reg.IsMatch(str));//返回false
為什么會返回false?
其實msdn官方定義已經(jīng)說了�����,只是它說得很官方而已��。這里需要我們注意一個關(guān)鍵點:此位置���。沒錯�����,是位置而不是字符�。那么結(jié)合官方定義和第一個例子來理解第二個例子:
因為a后面是b����,則此時返回了匹配內(nèi)容a(由第一個例子知道,只返回a不返回exp匹配的內(nèi)容)�,此時a(?=b)c中的a(?=b)部分已經(jīng)解決了,接下來要解決c的匹配問題了�����,此時匹配c要從字符串a(chǎn)bc哪里開始呢,結(jié)合官方定義�����,就知道是從子表達的位置向右開始的�,那么就是從b的位置開始,但b又不匹配a(?=b)c剩余部分的c��,所以abc就不匹配a(?=b)c了����。
那么如果要上面的進行匹配,正則應(yīng)該如何寫呢����?
答案是:a(?=b)bc
當然,有人會說直接abc就匹配上了��,還要這么折騰嗎�����?當然不用這么折騰����,只是為了說明零寬度正預測先行斷言到底是怎么一回事?關(guān)于其它的零寬斷言也是同一原理��!
補充三
(?=exp):零寬度正預測先行斷言����,它斷言自身出現(xiàn)的位置的后面能匹配表達式exp。
#匹配后面為_path�,結(jié)果為product
'product_path'.scan /(product)(?=_path)/
(?=exp):零寬度正回顧后發(fā)斷言,它斷言自身出現(xiàn)的位置的前面能匹配表達式exp
#匹配前面為name:����,結(jié)果為wangfei
'name:wangfei'.scan /(?=name:)(wangfei)/ #wangfei
(?!exp):零寬度負預測先行斷言,斷言此位置的后面不能匹配表達式exp�。
#匹配后面不是_path
'product_path'.scan /(product)(?!_path)/ #nil
#匹配后面不是_url
'product_path'.scan /(product)(?!_url)/ #product
(?!exp):零寬度負回顧后發(fā)斷言來斷言此位置的前面不能匹配表達式exp
#匹配前面不是name:
'name:angelica'.scan /(?!name:)(angelica)/ #nil
#匹配前面不是nick_name:
'name:angelica'.scan /(?!nick_name:)(angelica)/#angelica
小編也受夠了這個東西,等有好的東西再分享����,今天洗洗睡吧
您可能感興趣的文章:- 正則表達式中環(huán)視的簡單應(yīng)用示例【基于java】
- 正則應(yīng)用之 逆序環(huán)視探索 .
- 正則匹配原理之 逆序環(huán)視深入 .
- 正則基礎(chǔ)之 環(huán)視 Lookaround
- javascript 正則表達式分組、斷言詳解
- 正則表達式之零寬斷言實例詳解【基于PHP】
- 正則表達式斷言���、巡視(Assertions)��、正向斷言��、反向斷言介紹
- 正則表達式環(huán)視概念與用法分析
