7月15日�����,被《福布斯》雜志譽為“大數(shù)據(jù)運動的里程碑”的全球頂級大數(shù)據(jù)會議Strata Data Conference在京召開�����。第四范式先知平臺架構師陳迪豪受邀出席大會��,并分享了云深度學習平臺的架構與實踐經驗�����。
作為第四范式先知平臺架構師�����,陳迪豪活躍于Open stack����、Kubernetes、TensorFlow等開源社區(qū)�����,實現(xiàn)了Cloud Machine Learning 云深度學習平臺��,對如何進行云深度學習平臺架構有著深厚積累���。本次演講中�,他介紹了什么是云深度學習����?在經過實踐后,應該如何重新定義云深度學習�����?以及第四范式在這方面的應用和實踐。以下文章按照現(xiàn)場演講實錄整理����。
定義云深度學習平臺
什么是云深度學習?隨著機器學習的發(fā)展����,單機運行的機器學習任務存在缺少資源隔離、無法動態(tài)伸縮等問題����,因此要用到基于云計算的基礎架構辦事。云機器學習平臺并不是一個全新的概念�����,Google����、微軟、亞馬遜等都有相應的辦事����,這里列舉幾個比較典型的例子。
第一個是Google Cloud Machine Learning Engine�����,它底層托管在Google Cloud上���,上層封裝了Training���、Prediction、Model Service等機器學習應用的抽象����,再上層支持了Google官方的TensorFlow開源框架。亞馬遜也推出了Amzon machine learning平臺����,它基于AWS的Iaas架構,在Iaas上提供兩種差別的辦事���,別離是可以運行MXNet等框架的EC2虛擬機辦事����,以及各種圖象����、語音�����、自然語言處理的SaaS API���。此外,微軟提供了Azure Machine Learning Studio辦事��,底層也是基于本身可伸縮�����、可拓展的Microsoft Azure Cloud辦事����,上層提供了拖拽式的更易用的Studio工具,再上面支持微軟官方的CNTK等框架��,除此之外微軟還有各種感知辦事�、圖象處理等SaaS API,這些辦事都是跑在Scalable的云基礎平臺上面��。
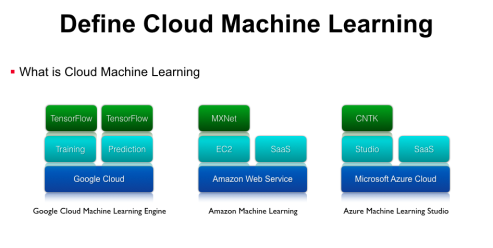
以上這些都是業(yè)界比較成熟的云深度學習平臺����,而在真實的企業(yè)環(huán)境中����,我們?yōu)槭裁催€需要實現(xiàn)Cloud Machine Learning辦事呢����?首先國外的基礎設施并不必然是國內企業(yè)可以直接使用的�,而如果只是當?shù)匕仓昧薚ensorFlow,那也只能在裸機上進行訓練�,當?shù)啬J沒有資源隔離,如果同時跑兩個訓練任務就需要本身去解決資源沖突的問題�。因為沒有資源隔離,所以也做不了資源共享�����,即使你有多節(jié)點的計算集群資源���,也需要人工的約定才能保證任務不會沖突�����,無法充分利用資源共享帶來的便當�����。此外��,開源的機器學習框架沒有集群級另外編排功能�����,例如你想用分布式TensorFlow時���,需要手動在多臺辦事器上啟動進程�,沒有自動的Failover和Scalling�。因此,很多企業(yè)已經有機器學習的業(yè)務,但因為缺少Cloud Machine Learning平臺,仍會有安排���、辦理�、集群調度等問題。

那么如何實現(xiàn)Cloud Machine Learning平臺呢����?我們對云深度學習辦事做了一個分層,第一層是平臺層�,類似于Google cloud��、Azure�����、AWS這樣的IaaS層�����,企業(yè)內部也可以使用一些開源的方案,如容器編排工具Kubernetes或者虛擬機辦理工具OpenStack���。有了這層之后���,我們還需要支持機器學習相關的功能,例如Training�、Prediction、模型上線���、模型迭代更新等��,我們在Machine Learning Layer層對這些功能進行抽象�,實現(xiàn)了對應的API接口���。最上面是模型應用層���,就可以基于一些開源的機器學習類庫���,如TensorFlow、MXNet等����。
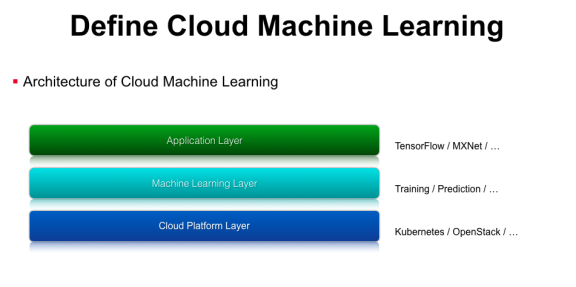
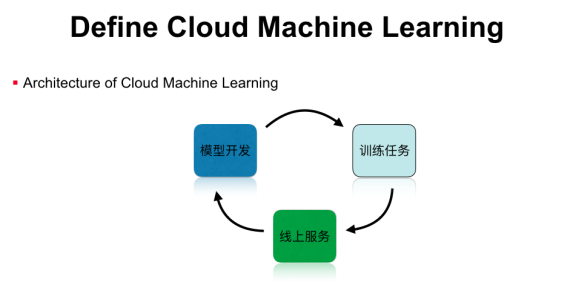
整個Cloud Machine learning運行在可伸縮的云辦事上,包行了模型開發(fā)����、模型訓練,以及模型辦事等功能�,形成一個完整的機器學習工作流。但這并不是一個閉環(huán)�����,我們在實踐中發(fā)現(xiàn)���,線上的機器學習模型是有時效性的��,例如新聞保舉模型就需要及時更新熱點新聞的樣本特征���,這時就需要把閉環(huán)打通�,把線上的預測結果加入到線下的訓練任務里�,然后通過在線學習或者模型升級,實現(xiàn)完整的機器學習閉環(huán)��,這些都是單機版的機器學習平臺所不能實現(xiàn)的�。
打造云深度學習平臺主要包羅以下幾個組件:首先是客戶端拜候的API Service,作為辦事提供方�,我們需要提供尺度的RESTful API辦事,后端可以對接一個Kubernetes集群���、OpenStack集群、甚至是自研的資源辦理系統(tǒng)�����?��?蛻舳苏埱蟮紸PI辦事后�,平臺需要解析機器學習任務的參數(shù)����,通過Kubernetes或者OpenStack來創(chuàng)建任務�����,調度到后端真正執(zhí)行運算的集群資源中����。如果是訓練任務��,可以通過起一個訓練任務的Container�����,里面預裝了TensorFlow或MXNet運行環(huán)境�����,通過這幾層抽象就可以將單機版的TensorFlow訓練任務提交到由Kubernetes辦理的計算集群中運行���。在模型訓練結束后��,系統(tǒng)可以導出模型對應的文件����,通過請求云深度學習平臺的API辦事��,最終翻譯成Kubernetes可以理解的資源配置請求,在集群中啟動TensorFlow Serving等辦事����。除此之外,��,在Google Cloud-ML最新的API里多了一個Prediction功能����,預測時既可以啟動在線Service,也可以啟動離線的Prediction的任務���,平臺只需要創(chuàng)建對應的Prediction的容器來做Inference和生存預測結果即可 �����。通過這種簡單的封裝,就可以實現(xiàn)類似Google Cloud-ML的基礎架構了�。

